

Int J Performability Eng ›› 2019, Vol. 15 ›› Issue (1): 252-260.doi: 10.23940/ijpe.19.01.p25.252260
Previous Articles Next Articles
Hongbin Wanga, Lei Hub, Xiaodong Xiea, Lianke Zhoua*( ), and Huafeng Lia
), and Huafeng Lia
Revised on
;
Accepted on
Contact:
Zhou Lianke
E-mail:zhoulianke@hrbeu.edu.cn
About author:Hongbin Wang received his PhD degree in computer application technology from Harbin Engineering University in 2010. He is currently an associate professor in the College of Computer Science and Technology of Harbin Engineering University. His research interests include information management, data integration, data space, semantic web, ontology and information system design.|Lei Hu received his Master’s degree in computer application technology from Wuhan University in 2004. He is currently a senior engineer of SERI. His research interests include information management, systems engineering, and system integration.|Xiaodong Xie is now studying for a Bachelor’s degree in computer application technology at the Harbin Engineering University in 2018. His research interests include deep learning, big data, AI, machine learning.|Lianke Zhou received his PhD degree in computer architecture from Harbin Institute of Technology in 2011. He is currently a lecturer in the College of Computer Science and Technology of Harbin Engineering University. His research interests include data visualization, dataspace, distributed computing and mobile computing.|Huafeng Li received his master degree in software engineering from Harbin Engineering University in 2016.His research interests include information management, data integration, and data classification.
Hongbin Wang, Lei Hu, Xiaodong Xie, Lianke Zhou, and Huafeng Li. Incremental Integration Algorithm based on Incremental RLID3 [J]. Int J Performability Eng, 2019, 15(1): 252-260.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
Table 1
Examples of data collection"
| No. | Outlook | Humidity | Play |
|---|---|---|---|
| 1 | sunny | high | no |
| 2 | sunny | high | no |
| 3 | overcast | high | yes |
| 4 | rainy | high | yes |
Algorithm 1
Update RLID3Tree (Root node of a RLID3 decision tree, Incremental data set)"
| 1. Input: Root node of a RLID3 decision tree, Incremental data set 2. Output: adjusted decision tree 3. declare a variable curNode, decision tree is used to represent the nodes in the traversal algorithm 4. set the curNode to the root node of the input RLID3 decision tree 5. adding the incremental data set to the sample feature code of the curNode 6. if (The classification of each sample is the same in the sample feature code set of the curNode) {//All samples are divided into similar 7. curNode is set to a leaf node, namely: the curNode attribute is set to null 8. class attribute value of curNode is set to the classification of the sample feature code set of the curNode 9. }else{//The samples belong to the category is not exactly the same 10. if (curNode is a leaf node) {//The attribute of the curNode is null 11. using the feature sample code set of the curNode, according to the formula (1), choosing the attribute with the maximum value of decision tree optimization ratio, the attribute of the curNode is set to the attribute 12. if (decision tree optimization ratio of the attribute of the curNode is 0) { 13. set the curNode to the leaf node, namely: the attribute of the curNode is set to null 14. class attribute value of the curNode is set to the most class of sample feature code set 15. }else{//The maximum value of decision tree optimization ratio is not 0 16. the attribute of the curNode as the attribute of the root node, call the RLID3 algorithm makeRLID3Tree (Sample feature set of the curNode, the attribute of the curNode) to build RLID3 tree} 17. }else{//the curNode is a branch node 18. using sample feature set of the curNode. According to the formula (1), selecting the attribute of the maximum value of decision tree optimization ratio, denoted as A 19. if(decision tree optimization ratio of A is 0){// 20. the curNode is set to leaf node 21. class attribute value of the curNode is set to the highest value in sample feature code set of the curNode 22. }else{//decision tree optimization ratio of A is not 0 23. The attribute of the curNodeis the same as A. 24. while(sample:sample feature code set of the curNode){ 25. add sample to the childrenTrainData[sample partition attribute's value number] array 26. } 27. for (j = 0; j< the number of the curNode’s available; j++) 28. the node that corresponds to the first j value is used as the root node of the sub tree, 29. call RLID3 algorithm, 30. updateRLID3Tree(the node that corresponds to the first j value, childrenTrainData[j]), subtree traversal 31. } 32. }else{//the attribute of curNode is not the same as A 33. the node that corresponds to the first j value is used as the root node of the sub tree, 34. call RLID3 algorithm, 35. updateRLID3Tree(the node that corresponds to the first j value, childrenTrainData[j]), subtree traversal 36. } 37. } 38. } 39. } |
Algorithm 3-1
PAR_WT algorithm"
| Input: data sets, the number of base classifiers Output: base classifier and its weight 1. Parallel implementation of the following procedure {//T times T said the number of base classifiers. 2. Being randomly divided into 10 parts of data. 3. Taking out the data set of 9 parts as the training set of the i base classifier. 4. Taking out the data set of 1 parts as the test set of the i base classifier. 5. Using RLID3 algorithm to train thei based classifier. 6. Usingthe formula (2), the classification accuracy of thei base classifier is calculated. 7. Using the formula (3), calculating the weight of thei base classifier. 8. } |
Algorithm 3-2
ParallelAndWeightSecond (pre-classification sample data)"
| Input: data sets, the number of base classifiers Output: base classifier and its weight 1. Initialization of the weight recorder, making aij=0 2. for (classifier: classifier set) {//classifier represents the i classifier 3. j = classifier.classify (instance) //j represents the classification results of the classifier for the sample 4. aij += classifier.getWeight();//aij plus the weight of the i classifier 5. } 6. Calculatingthe sum of each column of weight recorder 7. The maximum value of each column is used as the classification results of pre classified data. |
Algorithm 2
Weight recorder"
| Input: data set, trained classifier set Output: weight recorder 1. Initialization of the weight recorder, making aij=0 2. for (instance: data set) { 3. for (classifier: classifier set) {//classifier represents the i classifier 4. j = classifier.classify (instance) //j represents the classification results of the classifier for the sample 5. aij += classifier.getWeight();//aij plus the weight of the i classifier 6. } 7. } |
Algorithm 4
RLID3IncreEnsemble (incremental data set, initial stage of all base classifiers)"
| Input: incremental data set, initial stage of all base classifiers Output: adjusted base classifiers 1. Perform the following procedure T times in parallel{//T represents the number of base classifiers 2. Call algorithm 1, using the incremental data set to adjust the i base classifier to obtain the adjusted i base classifier 3. Test set of the i base classifier of initial stage is used as the test set of the adjusted i base classifier 4. Using the formula (2), the accuracy of the i base classifier is calculated. 5. Using the formula (3), the weight of the i base classifier is calculated. 6. } |
Table 2
Basic information of the data sets"
| Name | Instances | Attributes | Classifications | Missing Values |
|---|---|---|---|---|
| Letter | 20000 | 16 | 26 | No |
| HIV | 6590 | 8 | 2 | No |
| Nursery | 12960 | 8 | 5 | No |
| Tic-Tac-Toe | 958 | 9 | 2 | No |
| Connect-4 | 67557 | 42 | 3 | No |
| Chess | 3196 | 36 | 2 | No |
| Splice | 3190 | 61 | 3 | No |
| Mushroom | 8124 | 22 | 2 | Yes |
| Lymph | 148 | 18 | 4 | No |
| Breast-w | 699 | 10 | 2 | Yes |
Figure 1
Precision diagram of Incre_RLID3 algorithm"
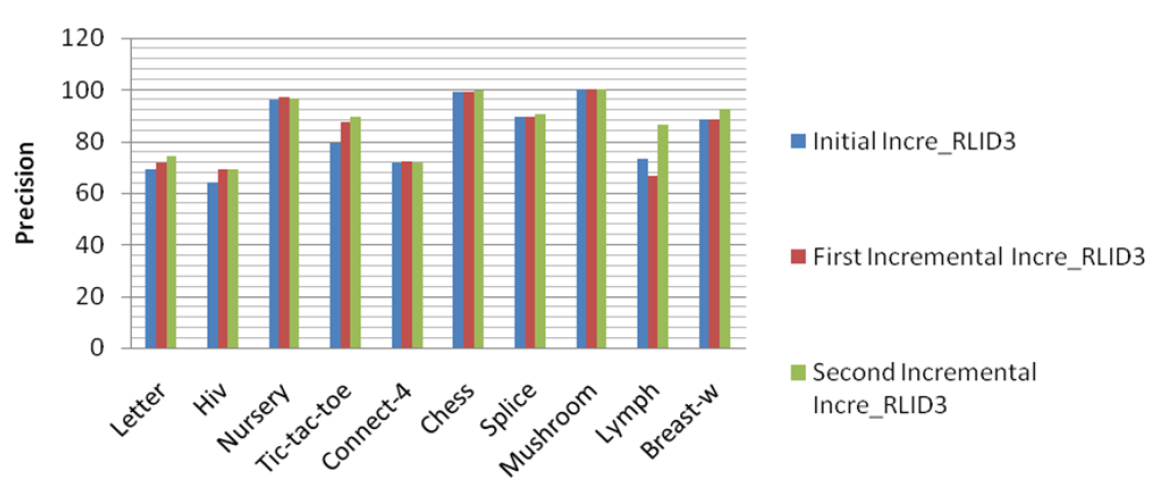
Figure 2
Precision diagram of PAR_WT algorithm"
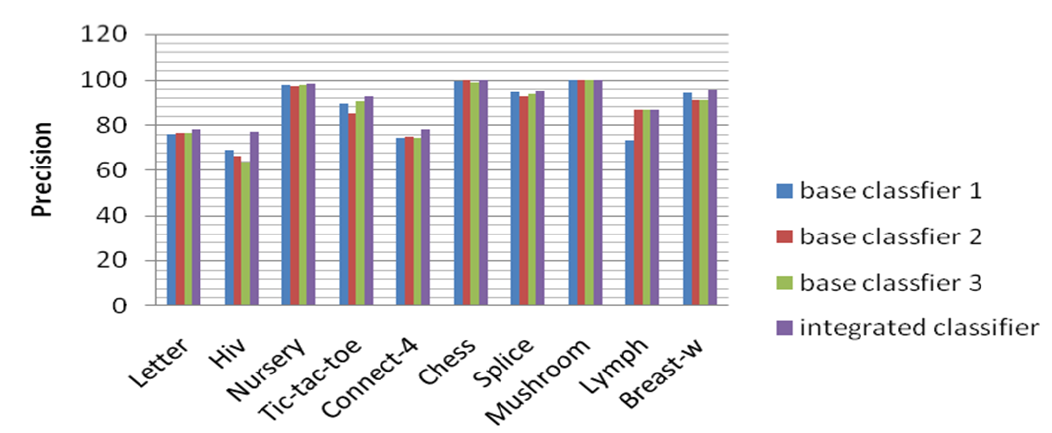
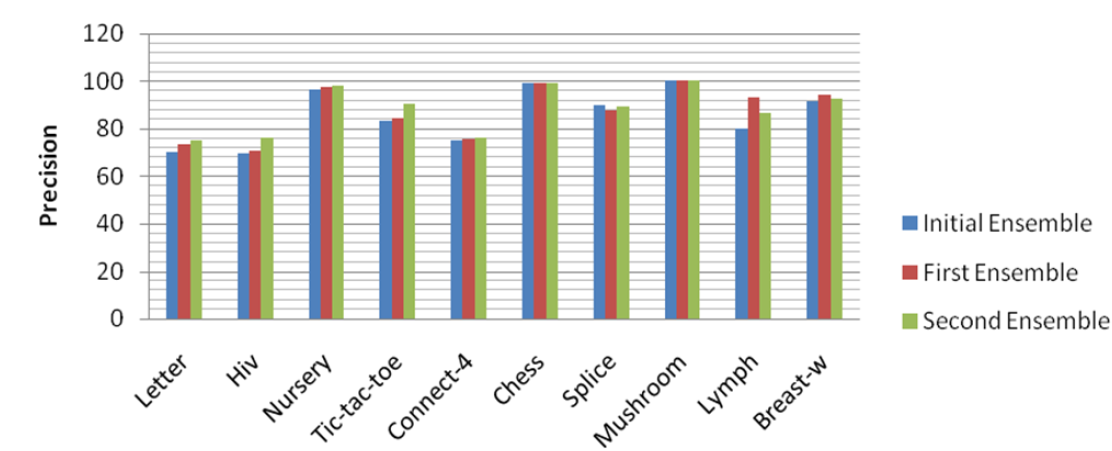
Figure 3
Precision of each stage of Incre_RLID3_ENM"
| [1] |
C. L. Cassano, A. J. Simon, L. Wei, C. Fredrickson, Z. H. Fan , “Use of Vacuum Bagging for Fabricating Thermoplastic Microfluidic Devices,” Lab on a Chip, Vol. 15, No. 1, pp. 62, 2015
doi: 10.1039/c4lc00927d pmid: 4256099 |
| [2] |
Y. Chen, J. Cao, S. Feng, Y. Tan , “An Ensemble Learning based Approach for Building Airfare Forecast Service,” inProceedings of IEEE International Conference on Big Data, pp. 964-969, 2015
doi: 10.1109/BigData.2015.7363846 |
| [3] |
B. Gu, V. S. Sheng, Z. Wang, D. Ho, S. Osman, S. Li , “Incremental Learning for ν-Support Vector Regression,” Neural Networks, Vol. 67, No. C, pp. 140, 2015
doi: 10.1016/j.neunet.2015.03.013 pmid: 25933108 |
| [4] |
Y. Guo, L. Jiao, S. Wang, S. Wang, F. Liu, K. Rong , et al., “A Novel Dynamic Rough Subspace based Selective Ensemble,” Pattern Recognition, Vol. 48, No. 5, pp. 1638-1652, 2015
doi: 10.1016/j.patcog.2014.11.001 |
| [5] |
B. Han, B. He, N. Rui, M. Ma, S. Zhang, M. Li , et al., “LARSEN-ELM: Selective Ensemble of Extreme Learning Machines using LARS for Blended Data,” Neurocomputing, Vol. 149, pp. 285-294, 2015
doi: 10.1016/j.neucom.2014.01.069 |
| [6] |
L. Hu, C. Shao, J. Li, H. Ji , “Incremental Learning from News Events,” Knowledge-based Systems, Vol. 89, No. C, pp. 618-626, 2015
doi: 10.1016/j.knosys.2015.09.007 |
| [7] | N. Li, Y. Jiang, Z. H. Zhou , “Multi-Label Selective Ensemble,” inProceedings of International Workshop on Multiple Classifier Systems, pp. 76-88, 2015 |
| [8] |
D. Peressutti, W. Bai, T. Jackson, M. Sohal, A. Rinaldi, D. Rueckert , et al., “Prospective Identification of CRT Super Responders using a Motion Atlas and Random Projection Ensemble Learning,” inProceedings of International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 493-500, 2015
doi: 10.1007/978-3-319-24574-4_59 |
| [9] | J.C. Schlimmer and D. H. Fisher , “A Case Study of Incremental Concept Induction,” in Proceedings of National Conference on Artificial Intelligence, pp. 496-501, Philadelphia, Pa, August 11-15, 1986 |
| [10] |
X. Z. Wang, H. J. Xing, Y. Li, Q. Hua, C. R. Dong, W. Pedrycz , “A Study on Relationship Between Generalization Abilities and Fuzziness of Base Classifiers in Ensemble Learning,” IEEE Transactions on Fuzzy Systems, Vol. 23, No. 5, pp. 1638-1654, 2015
doi: 10.1109/TFUZZ.2014.2371479 |
| [11] |
M. S. Zia and M. A. Jaffar ,“An Adaptive Training based on Classification System for Patterns in Facial Expressions using SURF Descriptor Templates, ” Kluwer Academic Publishers, 2015
doi: 10.1007/s11042-013-1803-3 |
| [1] | Ashu Mehta, Navdeep Kaur, and Amandeep Kaur. Addressing Class Imbalance in Software Fault Prediction using BVPC-SENN: A Hybrid Ensemble Approach [J]. Int J Performability Eng, 2025, 21(2): 94-103. |
| [2] | Vikas Kumar, Charu Wahi, Bharat Bhushan Sagar, and Manisha Manjul. Ensemble Learning Based Intrusion Detection for Wireless Sensor Network Environment [J]. Int J Performability Eng, 2024, 20(9): 541-551. |
| [3] | Shikha Singh, Sumit Badotra, and Nitin Arvind Shelke. Applying Machine Learning Techniques for Comparative Analysis of Various Diseases [J]. Int J Performability Eng, 2024, 20(6): 379-390. |
| [4] | Hannousse Abdelhakim and Talha Zied. A Hybrid Ensemble Learning Approach for Detecting Bots on Twitter [J]. Int J Performability Eng, 2024, 20(10): 610-620. |
| [5] | Rakesh Kumar, Sunny Arora, Ashima Arya, Neha Kohli, Vaishali Arya, and Ekta Singh. Ensemble Learning for Appraising English Text Readability using Gompertz Function [J]. Int J Performability Eng, 2023, 19(6): 388-396. |
| [6] | Neha Kohli and Tapas Kumar. Envisaging Alzheimer’s Disease Stage through Fuzzy Rank-Based Ensemble of Transfer Learning Models [J]. Int J Performability Eng, 2023, 19(6): 397-406. |
| [7] | K. Eswara Rao, G. Appa Rao, and P. Sankara Rao. A Weighted Ada-Boosting Approach for Software Defect Prediction using Characterized Code Features Associated with Software Quality [J]. Int J Performability Eng, 2022, 18(11): 798-807. |
| [8] | Sandeep Honnurappa and Bevoor Krishnappa Raghavendra. A Highly Robust Heterogenous Deep Ensemble Assisted Multi-Feature Learning Model for Diabetic Mellitus Prediction [J]. Int J Performability Eng, 2021, 17(11): 926-937. |
| [9] | Zhaoyue Zhang, An Zhang, Cong Sun, and Shanmei Li. Forecasting Airport Surface Traffic Congestion based on Decision Tree [J]. Int J Performability Eng, 2020, 16(5): 738-746. |
| [10] | Shibo Wang, Yong Li, Wenbo Mi and Ying Liu. Software Defect Prediction Incremental Model using Ensemble Learning [J]. Int J Performability Eng, 2020, 16(11): 1771-1780. |
| [11] | Minghua Jia, Xiaodong Wang, Yue Xu, Zhanqi Cui, and Ruilin Xie. Testing Machine Learning Classifiers based on Compositional Metamorphic Relations [J]. Int J Performability Eng, 2020, 16(1): 67-77. |
| [12] | Sizhe Huang, Huosheng Xu, and Xuezhi Xia. Imbalanced Remote Sensing Ship Image Classification [J]. Int J Performability Eng, 2019, 15(6): 1709-1715. |
| [13] | Xie Wei, Xu Huoxi, Peng Liping, and Lan Zhigao. Short-Range Wireless Network Communication and Application based on Decision Tree Algorithm [J]. Int J Performability Eng, 2018, 14(11): 2561-2573. |
|
||