







© 2021 Totem Publisher, Inc. All rights reserved.
1. Introduction
In recent years, crowdsourcing software testing has gained more and more attention in the field of black box software testing, such as web testing [1], APP testing [2-3], and QoE testing [4]. Because software testing needs a lot of manpower, time, and money, crowdsourcing mode can provide a lot of cheap labor, and a lot of attention is conducive to quickly finding all kinds of software problems. A lot of practice has proven that crowdsourcing software testing has a good effect in improving product quality and finding software defects [5-7]. Compared with black box software testing, the research progress of white box software testing in crowdsourcing software testing field is slower. The main reason is that white box crowdsourcing software testing requires more testing workers, and white box testing also lacks a credible testing environment.
White box crowdsourcing software testing, by calling crowdsourcing testing workers, uses crowdsourcing platform testing tools to design, write and execute test cases. The employer's distrust of the crowdsourcing software testing environment has become a major factor restricting white box crowdsourcing software testing. This distrust comes from the ignorance of potential attackers in crowdsourcing software testing platform. These attackers can sneak in crowdsourcing workers to steal the information of the project to be tested. Presently, the relevant research on crowdsourcing software testers mainly focuses on the research of the workers' ability, that is, the task is pushed to the right people to complete. It is a long-term and arduous task to study the credibility of test workers, which needs crowdsourcing test platforms for long-term monitoring [8-9].
We believe that the crowdsourcing test platform and the employer should establish such an understanding: "don't completely trust the crowdsourcing test workers", so this paper is more inclined to use relevant technical means to "encrypt" the test items before the crowdsourcing test tasks are distributed, that is, targeted transformation test items.
Code security is a big challenge in the field of white box crowdsourcing software testing. White box testing needs to release software source code to testers to meet the basic conditions of white box testing. Under this condition, white box crowdsourcing software testing usually decomposes the original project, builds multiple test task packages, and then distributes these task packages to test workers. The main idea of this kind of method is to break the whole into parts, disclose the parts and protect the whole. However, there are some defects in code protection by only decomposing the original project, which will be discussed in Section 3.
In order to further enhance the security of white box crowdsourcing software testing, this paper proposes to apply the idea and technology of code obfuscation to the field of white box crowdsourcing software testing. At the same time, in order to explain the reliability of our method, we also design a brute force cracking algorithm for white box crowdsourcing software test package and a restore algorithm based on clue search. By comparing the restoration effect of the project before and after the confusion, we can find that the task package after the confusion is much more difficult to restore than the original task. At the same time, in order to verify the impact of code obfuscation on test results, this paper also compares the reusability of test cases before and after obfuscation, and it finds that the reusability of test code will decrease with an increase in obfuscation intensity.
2. Background
White box crowdsourcing software testing is a new crowdsourcing software testing service mode. This mode aims to use the testing workers and testing resources provided by crowdsourcing software testing platform to carry out software testing such as unit testing, code review, performance testing, etc. [10]., which need to read the source code. At present, the research on crowdsourcing software testing application is often carried out in the field of black box testing, such as web crowdsourcing, mobile crowdsourcing, GUI crowdsourcing [11], etc. At the same time, the related research on crowdsourcing software testing process itself mainly focuses on crowdsourcing task design, crowdsourcing workers call, test report de duplication and so on. The main goal of these studies is to improve testing efficiency [12-13]. Few people pay attention to the security risks in crowdsourcing software testing.
Compared with white box crowdsourcing testing, black box crowdsourcing testing has excellent security, except for the reason that the training cost of black box crowdsourcing is lower than that of white box crowdsourcing. From the perspective of security, the related technology of code protection for black box programs has been relatively mature. Through the research of software encryption and decryption, we find that code protection technologies such as digital watermarking [14], instruction set modification, and virtualization are often used to create an encrypted black box software to prevent the code information obtained by the cracker [15]. However, white box testing directly exposes the code, and these traditional black box and "shell" technologies are difficult to apply to the current white box crowdsourcing testing scenarios. Therefore, to ensure the security of white box test code in crowdsourcing mode, we need to study specific protection technology.
White box crowdsourcing software testing highlights the security risks in crowdsourcing software testing. The employer needs to release the relevant code required for testing to the crowdsourcing software testing platform. Because the workers participating in the test are unknown groups scattered in the Internet, the crowdsourcing platform can not guarantee the reliability of personnel. In the black box crowdsourcing software testing scenario, the employer allows the testing workers to test the whole software to be tested. In the white box crowdsourcing software testing scenario, in order to prevent the testing workers from divulging all the employer's code, the employer decomposes the testing task into several smaller subtasks by decomposing the original project. Each worker is only allowed to test part of the code that has been allocated. For example, as shown in Figure 1, a complex program can be decomposed into multiple test tasks. This kind of method is called code segmentation under white box crowdsourcing testing. The idea of code segmentation is mainly used to hide the relationship between the local code and the whole code in the program, and to create information fragments to protect the security of the whole program. At the same time, the split program can be more suitable for the small task mode of crowdsourcing platform.
Figure 1.
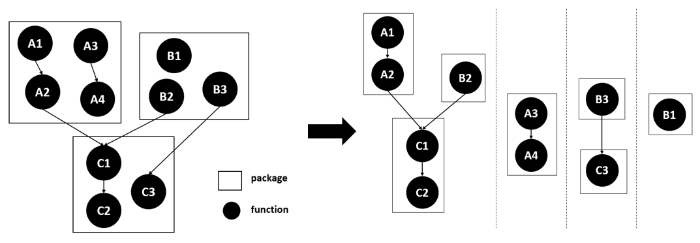
Figure 1.
Code segmentation
For the convenience of analysis, the example language selected in this paper is the golang programming language (later called Go language) designed by Google, which is known as the 21st century C language. Golang is a static strongly typed, compiled, parallel programming language with garbage collection function [16]. There is no concept of class and inheritance in golang's design. It mainly uses the concept of interface to realize polymorphism. At the syntax level, the reuse of golang is based on the package, that is, the main package where the main() function is located is used as the entry of the program. Whenever a function calls a function under this package, it is called directly by the function name. When it needs to call the function of another package, it needs to import the package and use "imported package name + function name" to call.
The minimum test unit of Go program is function. Go functions can be divided into two categories: one is called methods with callers and the other is functions without callers. For a function f to be tested, its package is p and its dependent package set is DP (dependent package). The function can be tested and run under the following conditions: F itself is complete, the declaration called by F under its package P is complete, and the declaration called by F in its dependency set DP is complete. Therefore, the most important components of Go program are declaration and package. For statically typed languages, code segmentation can prune the package P and its dependent package set DP where the function under test f is located through static analysis technology. It can delete the related declarations that f does not use to get a new package Pd and a new dependent package set DPd. Then, the code to be tested and its dependencies are encapsulated as a crowdsourcing test task and put into the crowdsourcing software test environment as a test task.
3. Weaknesses of Code Segmentation
In this section, we will analyze the defect of the code segmentation idea and further illustrate how attackers can use this defect to restore the decomposed program to the original program. White box crowdsourcing software test code segmentation mainly refers to: the employer can extract the software fragments that can be tested through static analysis [17-19] and other related technologies. These fragments are mainly composed of one or more functions to be tested and contain the dependent modules required by these functions to ensure that they can be tested in a given test environment [20]. However, there are some defects in decomposing source code to design task package:
1) The number of task packages that can be decomposed is limited by the size of the software to be tested. Fewer test units means smaller subcontracting, which also means reduction of the difficulty of restoration.
2) Only after segmentation without other processing, as long as all the task packages can be collected in the crowd testing environment, can the original project be restored.
3.1. Crowdsourcing Task Restoration based on Clues
Suppose a go program contains n test units, then the program can build up to n test tasks. Through code segmentation technology, these n task packages only contain necessary program information. However, without modifying the program code, these n tasks contain all the declarations of the original program, which means that the original program can be restored as long as the declarations are arranged in a certain order. An ideal condition for restoring the original program is that the original program is divided directly without modifying the original code.
The task package after code segmentation often contains a lot of clues because crowdsourcing employer does not modify the original code. For example, different task packages contain the same function, or different task packages use the same declaration, or some similar code style. For example, task package A contains structure graph and defines and functions addvex and AddEdge. Task package B also contains structure graph and defines functions deletevex and deleteedge. Obviously, these two task packages are splitting the same go code package. Based on such clues, attackers can quickly merge task packages to restore the original program (Figure 2). This kind of algorithm analyzes the relationship between task packages by comparing the statements in n task packages.
Figure 2.

Figure 2.
Code restore
It can be seen that although the code segmentation idea decomposes the program into smaller sub fragments, there are many clues between these sub fragments, which can effectively guide the attacker to restore the original program. Attackers can use their own unlimited personal time to piece together the code. In order to improve code segmentation, we first need to analyze the difficulty and cost of code being restored. Thread based restoration can piece smaller program fragments into larger ones. But when there is no clue or the clue is not obvious, it is often difficult to restore the program. Especially for thread based restoration, because the thread is a static module such as name and variable, it needs to be manually reconfirmed by the attacker, so a large part of the overhead is spent on the time of manual confirmation.
3.2. Crowdsourcing Task Restoration based on Directed Acyclic Graph
Crowdsourcing task restoration based on directed acyclic graph is essentially a violent restoration method, which can ignore the clues between program fragments. It is known that a go program with n declarations is put into the crowdsourcing software testing environment after code segmentation. Suppose that an attacker obtains all the task packages. Then, the attacker has the ability to restore the original go language program. First of all, go program can be regarded as a directed acyclic graph composed of multiple packages. Arrow A points to B, indicating that package B depends on package A. As long as the corresponding declaration is put into the corresponding package, the original program can be restored. The attacker can regard the program as a labeled directed acyclic graph with m different points and k edges, and fill n statements into m points. In many permutations, there must be effective permutations so that the new program is equivalent or completely consistent with the original program.
Suppose the attacker obtains three non-duplicate statements A, B, and C, and now puts these statements into a package arrangement. There are 5 cases where the declarations are arranged into packages (Figure 3): 3 in the same package, 3 in 2 packages and 3 in 1 package. A go program with n declarations contains at least one package and at most N packages. When the attacker doesn't know the distribution of claims, he first needs to determine the number of packets M. After the number of packages m is determined, the declaration restore will be changed to put n declarations into m packages. At this time, the dependencies between packages have not been considered. These packages can be regarded as the same lattice, but the declarations are different from each other. The problem can be seen as n different balls filling into m identical baskets. The number of permutation combinations produced by such permutations is called Stirling number (S):
S(n,m)=S(n-1,m-1)+S(n-1,m)*m (n>1,1<=m<n)
Figure 3.
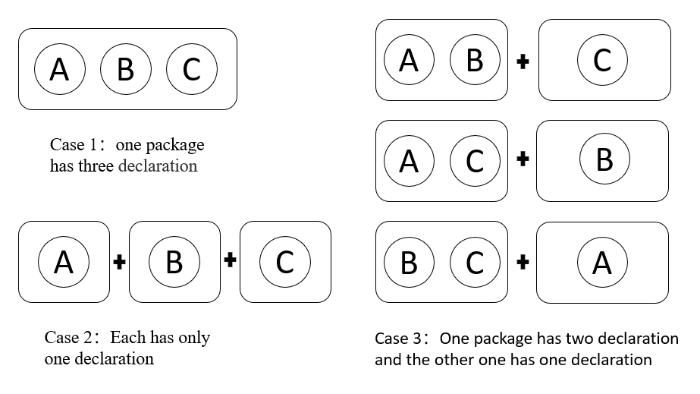
Figure 3.
Declaration in different packages
Table 1. Package generation algorithm
| Algorithm: package generation algorithm |
|---|
| function: DeclInPkgs Input: declaration list of N declarations Output: package list of M packages |
| 1. func DeclInPkgs (str [ ]string, m int) [ ][ ][ ]string{ 2. var result [ ][ ][ ]string 3. n:=len(str) 4. split(n,m) // Decomposing a positive integer n into m positive integers (recursion) 5. newstr:=wholeArrange(str) // The str is fully arranged to generate a newstr [] string 6. for _,i:=range newstr{ 7. According to the M numbers, extract the declaration from the declaration list I and package it into a package 8. Put the generated new package into the package list } 9. return result 10. } |
The Stirling number represents the kind of N declarations into m packages. The specific permutation process is calculated by an O (n!) permutation function. If n statements are put into m packages, it can be regarded as the solution of decomposing positive integer n into m positive integers. For example, if 4 declarations are put into 2 packages, there are two results: two packages can have 2 declarations each; or one package can have 3 declarations, and the other package can have 1 declaration. The specific packet arrangement algorithm is shown in the following Table 1.
Figure 4
Figure 4
shows that a change of packet permutation results in the interval of packet number
Figure 4.

Figure 4.
Relationship between declaration, package and Stirling number
After all the packages are determined, we only need to further establish the dependency graph relationship between packages to restore the program. The essence of dependency graph of go language program is a directed acyclic graph. The calculation formula of the kind of directed acyclic graph with n nodes is as follows:
Given that a directed acyclic graph has n vertices, then the number of edges in the graph is
Figure 5.
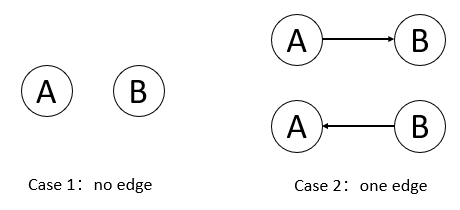
Figure 5.
Directed acyclic graphs with two points
When a directed acyclic graph withn-1 points is extended to n points, the relationship between thenth point and the existingn-1points has three cases: the new point to the existing points, the existing points point to the new point, and there is no edge between the two points. There are
Figure 6.
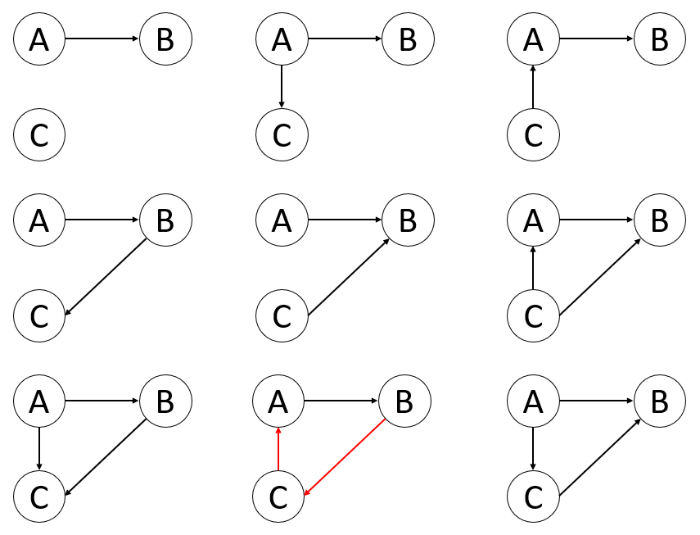
Figure 6.
Three points constitute a directed acyclic graph
Table 2. Directed Acyclic Graph Create Algorithm
| Algorithm: Directed Acyclic Graph Create |
|---|
| Function: DAGCreate Input: Directed acyclic graph olddag with n-1 vertices Output: The set newdag of directed acyclic graphs with n vertices |
| 1. func DAGCreate (OldDAG *OLGraph) []*OLGraph{ 2. result []*OLGraph 3. Create Trie(n-1) // Create a trident tree 4. NewEdges=SearchTree() //Each edge relation of the tree is stored in the frontier series table 5. for _,i:=range NewEdges{ 6. g=CopyOLGraph(OldDAG) //Copy the Graph 7. NewDAG=AddNewEdges(g)// Add all new edges 8. if nocyc(NewDAG){ // Judge whether there is a cycle 9. result=append(result,NewDAG)} 10. } 11. return result 12. } |
Figure 7.
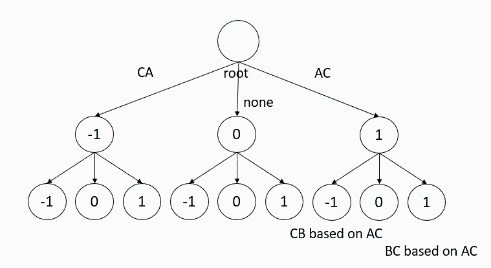
Figure 7.
Trigeminal tree represents the relationship between two points
According to the above analysis, it can be seen that the reduction of statements to packages and the generation of directed acyclic graphs from the relations between packages are solvable in super polynomial time without using clue analysis program. As the number of claims increases, the cost of violent restoration will increase rapidly. The number of final programs b(n) consists of two parts: one is the number of packets that can be composed of declaration numbers, and the other is the total number of labeled directed acyclic graphs [21] that can be composed of these packets.
The difficulty of restoration can be regarded as the reciprocal of the proportion of the graph that makes the program equivalent to the original program in all graphs. The essence of clue based restoration is to find the relationship between statements by searching, so as to generate the corresponding subgraph, which reduces the amount of calculation. Therefore, the main shortcomings of the segmentation idea are:
1) The code can be restored after segmentation, and the difficulty of restoration is related to the number of fragments that can be decomposed by the program itself.
2) After segmentation, the clues between codes will greatly reduce the difficulty of restoration. The main reason is to determine the position of the unknown point (declaration package) and the edge (dependency) in the graph, thus reducing the uncertainty of the graph. The ability to find clues depends on the efficiency of the attacker's analysis algorithm.
4. Approach
In the previous section, we pointed out the shortcomings of the code decomposition idea. Attackers can restore it according to clues or violence by collecting task packages. In this section, in order to increase the difficulty of cracking and even affect the results of cracking, we propose to introduce code obfuscation based on existing subcontracting to improve the security of white box crowdsourcing software testing tasks.
4.1. Code Obfuscation Theory
Definition of code obfuscation[15]: code obfuscation is to convert program P into an equivalent program T(P)through obfuscation transformation T. Let i be an element of the set I of all the inputs of program P, only if
Figure 8.
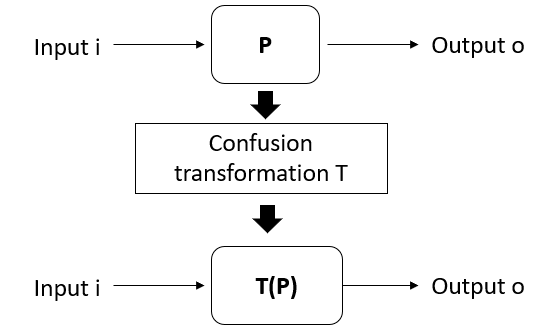
Figure 8.
Code Obfuscation
Common code obfuscation methods are: (1) layout obfuscation - changing the readability of source code by modifying function name and variable name. (2) Control flow confusion mainly refers to modifying loop statements - judging statements and providing opaque predicates to change the control flow to a certain extent. (3) Data obfuscation refers to the obfuscation of numerical value or data structure in program operation. (4) Preventive obfuscation, through the study of some known anti obfuscation software, provides some improvement programs for existing obfuscation. The common preventive obfuscation is to create a special instruction set in the virtual machine.
By modifying the source code, code obfuscation can effectively resist the cracking of the source code by reverse tools. Generally speaking, code obfuscation mainly acts on the completed program and is mainly used to add "shell" to the black box program. We think that its special idea can also be used in the special environment of white box crowdsourcing software testing.
Obfuscated Target: any form of code protection that cannot achieve comprehensive protection, the defender designs the corresponding protection scheme according to the known attack means. Therefore, before code obfuscation, we must first identify the object or target to be protected. The main purpose of white box crowdsourcing software testing is to hope that testers can write test cases. We are willing to complete the part that workers are assigned, but we are opposed to attackers getting larger units. A larger unit means a more complete module of the original program, so the obfuscation goal is to hide the relationship between these modules so that the computational cost of restoration is greater and even the original program cannot be restored. The test cases obtained in crowdsourcing software testing environment can effectively affect the unambiguous programs.
Confusion evaluation index:the traditional evaluation index of code confusion is mainly proposed by Collberg, which is composed of Intensity, Flexibility, Concealment and Cost [15,22]. Intensity mainly refers to the complexity of the program after confusion, which will be more complex. Elasticity refers to the resistance of the program to the analyzer after obfuscation. The stronger the resistance, the better the obfuscation algorithm. The stronger the concealment, the less likely the analyst is to realize that the program is confused. The cost refers to the additional cost of the confused program when compared with the original program. This value will not be less than the cost of the unambiguous program itself. Therefore, the cost should be a small difference to prevent the confusion of the program running too much cost.
In the new scenario of white box crowdsourcing software testing, new requirements for code obfuscation are put forward.
1) Intensity: first of all, the intensity needs to be paid special attention in this environment. If the program is modified too complex through code obfuscation, it will affect the test workers' testing of the program, so the obfuscation intensity needs to be as low as possible.
2) Flexibility: as an evaluation index of code obfuscation algorithm against analysis tools, resilience is still an important index in the new environment.
3) Concealment: concealment, as a special index to reduce the possibility of confusion, should also be retained.
4) Calculation Cost: since the obfuscated code inserted in the program fragment may not be added to the final program, the overhead caused by obfuscation in the test process can be ignored. Runtime overhead is not an indicator of crowdsourcing white box software testing.
5) Crowdsourcing Cost: although we don't pay attention to runtime overhead, it is replaced by cost, which is the cost of crowdsourcing software testing. Here, it mainly refers to the cost of code confusion compared with unambiguous programs. The cost is mainly the cost of time, money or manpower.
6) Test Effectiveness: the fundamental purpose of white box crowdsourcing software testing is to collect test cases. The test cases collected by the confused program in crowdsourcing environment can reuse the program before confusion. If code obfuscation results in too many modifications to the program, and the test cases cannot be reused in the original program, then such obfuscation is invalid. Therefore, such as control flow obfuscation, data obfuscation and other obfuscation algorithms that directly insert into the source code to change the running results of the source code often make the test results unconvincing.
4.2. Code Obfuscation Approach
Under the condition of white box crowdsourcing software testing. Each task package contains complete testable code fragments. In order to ensure the smooth progress of the test, the employer must ensure the readability of these codes. Traditional code obfuscation techniques are often used to resist code decompilation and increase code reading difficulty. Now, in the white box crowdsourcing environment, we hope that through the code obfuscation technology, we can make the program difficult to be restored as a whole as far as possible, and at the same time do not damage the readability of the code as far as possible.
Layout obfuscation is used in a large number of obfuscation tools. Although the original code information is modified, it will not affect the operation of the program, but it will make it difficult for attackers to read and understand. Layout obfuscation is considered as an unreliable obfuscation in the traditional code obfuscation. The main reason is that modifying the names of variables and functions can not resist the analysis of memory, and its security is not high. The main reason is that the internal code execution of the released black box program has been fixed. Reverse analysis can basically ignore the code layout, which only affects the reader's experience. Is layout confusion effective in crowdsourcing mode?
White box crowdsourcing software testing divides the code and then puts it into the test environment. The task package of these code fragments contains testable elements, but we hope that after the attackers merge, these larger code fragments are difficult to run. The purpose of obfuscation is to hide the original relationship between the code, or make the restored code unable to run. A typical method of layout obfuscation is to modify the name of the declaration. In this way, all kinds of declarations in the original code are modified. On one hand, the program that can be restored through clues loses the clue of name; on the other hand, the program that wants to restore must restore these changed declarations again, because in static code, different names will point to different memory spaces when the program is running. The original code can be restored as long as it is placed in a specific location. Now, after layout confusion, the attacker's algorithm of restoring based on clues has lost its effectiveness, and the attacker needs to restore the declared name constantly so that the restored code can successfully form a whole.
For example, the orthogonal list graph contains two algorithms: DFS (depth first search) and BFS (breadth first search). Suppose that the two functions are divided into different task packages without any modification. These two task packages contain olgraph and both use olgraph. From these clues, the attacker can infer that the two functions belong to different functions defined by the same package. Now let's modify the name of the related declaration in one of the groups. For example, change the olgraph name in BFS to tree (Figure 9). It feels like a tree structure search. If the attacker does not spend time reading the code carefully, but only relies on the name for analysis, he will find that it is difficult to find such clues only through the declared name. More importantly, in the same running program, olgraph and tree will be divided into two different memory instead of representing the same variable.
Expansion: the idea of expansion is mainly based on the basic principle that the more points in the graph, the more situations in the graph. By introducing more content into the task, the cost of restoration is greatly increased (Figure 10). For example: add an extra code prepared in advance in the original project, or directly copy some task packages to modify their names, and then put them into the test environment. Although this method increases the cost of code restoration, it also requires crowdsourcing testers to test more programs, which increases the cost of crowdsourcing software testing. Since the extension itself does not modify the original code, the attacker can still restore the original project.
Figure 9.
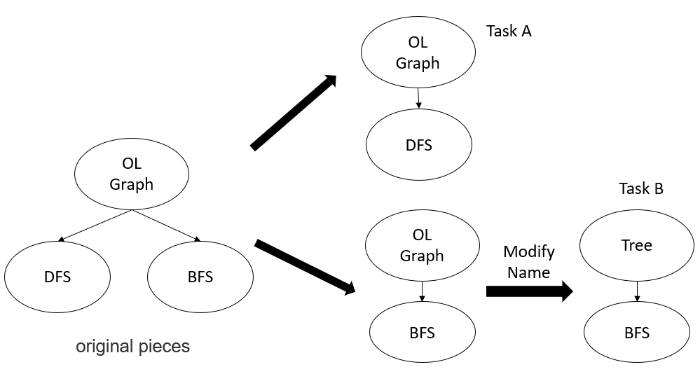
Figure 9.
Layout confusion
Figure 10.
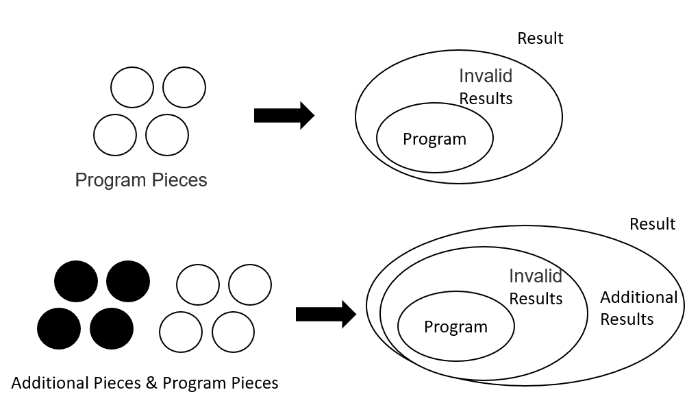
Figure 10.
Expansion
Misleading: misleading is an enhancement of the above two methods in crowdsourcing software testing. The idea of this kind of method is to guide the attacker to restore another target program. The main goal of this kind of method is to change the result that can be restored into another misleading result (Figure 11).
Misleading can effectively make up for the situation that the program can't run because of modifying the name. If the attacker can't restore any executable program fragments, then the attacker will suspect that these code fragments have been modified. Therefore, by misleading, the defender guides the attacker to restore a misleading program to replace the real protected program, so as to deceive the attacker.
Figure 11.
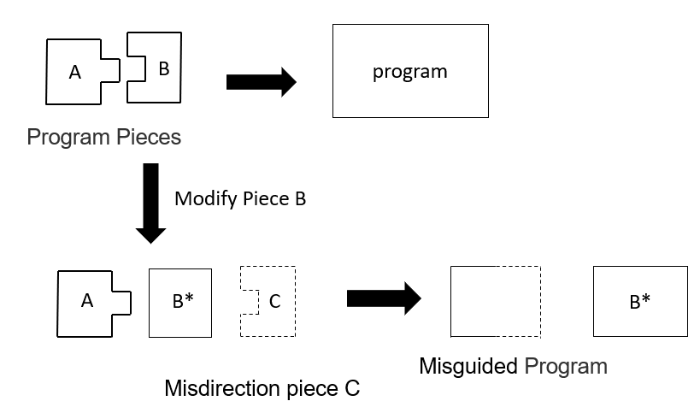
Figure 11.
Misleading leads to new results
Data obfuscation: Data obfuscation is a kind of controversial code obfuscation in crowdsourcing software testing. Data obfuscation is mainly used to resist attackers using code similarity detection technology. Such techniques can match statements with similar structures in code. Simple name modification can not resist this kind of attack against statement structure. The main reason for this dispute is that the data structure in the source code has been modified, which may lead to some test cases obtained in crowdsourcing mode that cannot be reused in the original program.
5. Experiment
This chapter aims to verify whether the above confusion idea can play a protective role in the white box crowdsourcing software testing environment. We divide and obfuscate a go language program with 100 declarations. This program is the complete version of the brute force program above. The program contains 93 function declarations, 7 general declarations, 65 test cases, and 37 task packages that are divided according to their dependencies (Table 3). Verification of its resistance to clue search and brute force cracking are used to verify the effectiveness of our confusion ideas. In order to analyze the relationship between the declarations in the stored program, the experiment transforms the relationship between the declarations into a directed acyclic graph for storage. Finally, in order to facilitate the experimental observation, we use graphviz to convert these directed acyclic graphs into dot language and generate pictures (Figure 12).
Table 3. Pragram Overview
| Package | Function | General Declation | Test Cases |
|---|---|---|---|
| api | 9 | 0 | 6 |
| bucket | 47 | 1 | 38 |
| decl | 9 | 0 | 2 |
| dirgraph | 3 | 1 | 2 |
| olGraph | 18 | 3 | 14 |
| tree | 7 | 2 | 3 |
Figure 12.
Figure 12.
Declaration relation generated by dot language
In order to verify the relevant methods of code obfuscation in the previous chapter, we designed three groups of controlled experiments. They are the impact of layout confusion or misleading on the results of restoration, the impact of proliferation on the efficiency of restoration, and the impact of data confusion and layout confusion on the test results.
The main goal of layout confusion and misleading is to deal with the impact of restore results. The former makes the restore results unable to unify variables or functions in static files and makes the runtime memory unable to unify. The latter is mainly in the technology of layout confusion, putting some prepared misleading code into the task package to guide the attacker to restore the new project. We select 30 task packages from 37 task packages, modify 90 of them, and then randomly rename the packages in which these declarations are located. We ensure that the programs under the same task package can run. For example, we change the tree package and function createarctree to star package start function, and the number of declarations is still 100, but the number of packages is increased to 37. Before conversion, 56 clues can be found by using clue search analysis. After conversion, all these clues are hidden by renaming, which eventually makes the clue search algorithm invalid.
Proliferation increases the cost of related cracking algorithms by providing additional testing tasks. As shown in Figure 13, the total number of declarations is increased from 90 to 200 by adding artificially designed irrelevant declarations to the existing six go packages. At this time, we use the clue search algorithm to search for clues, and the search results add 50 extra clues that we added in advance. At the same time, in order to verify the impact of statement growth on brute force cracking algorithm. We run in a 4-core 16g memory windows 10 environment for many times, and the result of running time is shown in Table 4.
Table 4. Impact of the increasing number of declaration on brute force cracking algorithms
| Declaration Number | The number of directed acyclic graphs | Run time (s) |
|---|---|---|
| 1 | 1 | 0.06 |
| 2 | 4 | 0.079 |
| 3 | 35 | 0.224 |
| 4 | 715 | 3.499 |
| 5 | 35382 | 193.588 |
| 6 | 3781503 | 6451.76 |
Figure 13.
Finally, in order to test the impact of code obfuscation on test results, we reuse the existing 65 test cases for layout obfuscation and data obfuscation, of which 65 functions can be used for layout obfuscation, and the functions that have been used for layout obfuscation (Here is mainly name obfuscation) can be reused by making corresponding name changes to the test cases. There are 57 functions that can be used for data obfuscation. In the experiment, we use two data obfuscation methods: one is incremental method, which mainly inserts redundant variables into the original data structure so that the data structure needs additional memory space. The other is the modification method, which mainly modifies the similarity of existing variable types, such as transferring integer to floating-point type, replacing variable with pointer variable, etc. When we migrate the existing test cases to these two situations, most of them are not available. Redundant variables often cause the problem of initializing spatiotemporal pointers, while the type change caused by modification requires comprehensive modification for test cases. The final results of the three confusions are shown in the Figure 14. Generally speaking, data obfuscation is more intensive than layout obfuscation, and the greater the intensity of obfuscation, the greater the impact on reuse before and after test cases.
Figure 14.
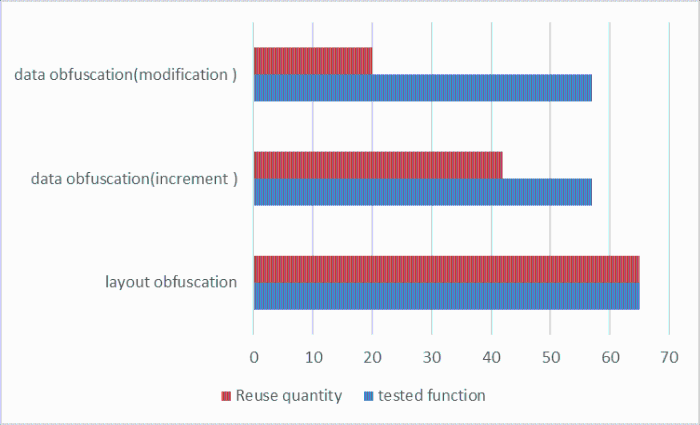
Figure 14.
Influence of layout confusion and data confusion on test results
6. Conclusion
Presently, the main reason hindering the development of white box crowdsourcing software testing is the leakage of source code. In order to reduce the risk brought by the overall leakage of the project, the employer often uses the method of code segmentation to reduce the amount of code each worker gets as much as possible. These test tasks can be directly restored to the original program without special treatment, and the difficulty of cracking comes from two sources: one is to collect these program fragments from the crowdsourcing environment, and the other is the difficulty of restoring the program itself, which is mainly determined by its complexity. In this paper, code obfuscation is taken as a special protection scheme. By increasing the complexity of the program, the cost of restoring is increased, or the attacker is directly misled to restore the wrong program. The influence of different confusion methods on the protection effect is shown in Table 5.
Table 5. Influence of different confusion methods on testing
| Confusion scheme | Impact on reduction results | Impact on testing |
|---|---|---|
| Layout confusion | Affect the result of reduction | The test cases are easy to reuse and hardly increase the labor cost. |
| Expansion | Increase restore overhead | Test workers need to design more test cases to increase labor costs. |
| MisLeading | Increase restore overhea & Affect the result of reduction | Test workers need to design more test cases to increase labor costs. |
| Data confusion | Affect the result of reduction | Test cases are difficult to reuse. |
We think that it is a long-term process to screen the integrity of testers and build a trusted environment for a crowd testing platform. Code obfuscation is protected from the code itself, which can provide a good protection scheme in the development stage of white box crowdsourcing software testing. However, code obfuscation does not guarantee that the program cannot be restored in the end, and the scheme provided above can only resist the corresponding attack mode. At the same time, code obfuscation modification often has an impact on the results of crowdsourcing software testing, and the higher the intensity of obfuscation, the more profound the impact [23]. There is no large-scale research on the relationship between crowdsourcing test cases and code obfuscation. Even if the definition of code obfuscation requires the program before and after obfuscation to be consistent in function, there is no relevant theoretical research to prove that the test case of a program can be completely equivalent to the program after code obfuscation. At the same time, the increase of crowdsourcing cost caused by confusion is also a problem [12]. It is difficult to measure where the balance point between efficiency and safety for crowdsourcing benefits is [23].
In the next step, we will further study the possible security risks in crowdsourcing, attack methods against these security risks and related solutions. We hope that white box crowdsourcing software testing will develop in a more efficient and secure direction, and create a new software engineering model for open collaboration on a larger scale by continuously integrating test resources on networks [24].
Reference
Gardlo, B., Egger, S., Seufert, M. and Schatz, R. Crowdsourcing 2.0: Enhancing execution speed and reliability of web-based QoE testing
Research progress of crowdsourced software testing
and rethinking-an industrial investigation on crowdsourced mobile application testing
Crowd anatomy beyond the good and bad: Behavioral traces for crowd worker modeling and pre-selection
A comparative study of white box, black box and grey box testing techniques
Zogaj, S., Bretschneider, U. and Leimeister, J.M. Managing crowdsourced software testing: a case study based insight on the challenges of a crowdsourcing intermediary
Collberg, C.S. and Thomborson, C. Watermarking, tamper-proofing, and obfuscation-tools for software protection
and tamperproofing for software protection: obfuscation, watermarking, and tamperproofing for software protection
The go programming language
Cai, H. and Santelices, R. Abstracting program dependencies using the method dependence graph
Type slicing: An accurate object oriented slicing based on sub-statement level dependence graph
Source code modularization: theory and techniques
Robinson, R.W. Counting unlabeled acyclic digraphs
Barak, B. Hopes, fears, and software obfuscation
needs and practice

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}