



1. Introduction
With fast development and wide application of database technology, the amount of data accumulated by various industries is increasing [1-2]. People have estimated that the amount of information in the world will double every 20 months, and the number and size of databases are growing at a faster rate. Faced with such a large amount of data, people hope to extract valuable information or knowledge from massive data to provide the reference for decision makers [3]. However, due to data entry errors, data fusion and migration of different representation methods, etc., the system inevitably has redundant data, missing data, uncertain data,and inconsistent data, etc. [4]. These data are collectively referred to as “dirty data”, which are derived from different channels leading to an increase in similar duplicate records, which seriously affects data utilization and decision quality. The detection and cleaning of similar duplicate records have become a hot research issue in the fields of data warehousing and data mining.
In recent years, scholars have proposed some new methods for database duplicate record detection. For example, Song et al. proposed a big data similar duplicate record detection algorithm based on the MapReduce model. The traditional SimHash algorithm was improved by using Chinese lexical analysis technology, Delphi method and word frequency-reverse file frequency algorithm. This method can solve the problems of the slow keyword extraction speed and low accuracy and the weight calculation accuracy [5]. The traditional SimHash algorithm was optimized by the inverted index algorithm to improve the matching efficiency of similar duplicate records. The Map function and the Reduce function were defined on the cloud platform by using the proposed MP-SYYT algorithm, and the parallel detection and direct output of big data similar repeated records were realized in the cloud environment by using the MapReduce model. Since the MP-SYYT algorithm had a great relationship with the Map function and the Reduce function setting, the actual recall rate and the precision rate were low and unstable [6]. An improved algorithm for high-dimensional similar duplicate record detection based on R-tree index was proposed. The R-tree was used to construct the index to preserve the high-dimensional space characteristics of the record, and the distance algorithm for measuring the similarity of the records was improved to avoid the influence of high-dimensional data sparsity. This method was more efficient for small-scale databases, but its detection efficiency was not ideal for large-scale databases.
Aiming at the above problems, a database repeat recording detection method based on IQPSO algorithm is proposed. The main research work is as follows.
(1) For the database duplicate record detection problem, by constructing an entropy measure in terms of the similarity between objects, the weight of each attribute in the database original data set is evaluated, and the key attribute set is selected. According to the key attributes, the data is divided into disjoint small data sets, and the similar repeated records are detected by the support vector machine method in each small data set.
(2) For the problem that the detection accuracy of the support vector machine algorithm is not high, the IQPSO algorithm is used to optimize the parameters of the support vector machine to obtain the optimal parameters of the support vector machine. The repeated record detection model is constructed by training the classifier according to the optimal parameters.
2. Database Repeat Record Detection Method based on IQPSO Algorithm
2.1. Similar Repeated Record Detection based on Entropy Feature Attribute Partitioning
By constructing an entropy metric in terms of the similarity between objects, the weight of each attribute in the original dataset of the database is evaluated, and the unimportant or noisy attributes are removed. The key attribute subsets are optimized, and the attribute dimension is reduced. According to the key attributes, the large data set in the database is divided into multiple disjoint small data sets, and the similar repeated records are detected by the support vector machine method in each small data set. The specific process is as follows:
Suppose there are $n$ objects ${{x}_{i}}{{({{x}_{i1}},\cdots ,{{x}_{im}})}^{T}}$ in the $m$ -dimensional feature space in relation $R$, and the distance between the two objects is measured by the norm distance [7]:
It can be seen from the formula that the distance ${{L}_{1}}$ is the absolute distance when $p=1$ ; when $p=2$ , the distance ${{L}_{2}}$ is the Euclidean distance; the distance is the Chebyshev distance when $p\to \infty $. Considering when $p\ge 2$, the distance between two objects ${{x}_{ik}}$, ${{x}_{jk}}$ in the $k$-dimensional feature space converges to zero as the dimension increases. The distance between two objects is calculated using the ${{L}_{1}}$ distance, which is obtained by Equation(1).
Assume that the database data feature set of the $m$-dimensional space is $F=\{{{X}_{1}},\cdots ,{{X}_{m}}\}$ . In order to remove the influence of different dimensions on the distance, the standard deviation of the characteristic variable ${{X}_{k}}$ is introduced ${{S}_{k}}=\sqrt{\frac{1}{m}\sum\limits_{k=1}^{m}{{{({{X}_{k}}-\bar{X})}^{2}}}}$, $\bar{X}$ is the average value of the characteristic variable ${{X}_{k}}$. In addition, the normalization coefficient $\lambda$ is introducedin the consideration of dimensional normalization of the distance.The distance between two objects can be transformed by Equation(3).
According to the distance metric given by Equation(3), the similarity between two objects can be described as Equation(4).
In Equation(4), ${{e}^{(\cdot )}}$ represents the approximation adjustment coefficient, and parameter $\sigma $ is used to adjust the attenuation property of the similarity. The smaller the $\sigma $, the faster the similarity decays with distance.
Equation(4) shows that when $d({{x}_{i}},{{x}_{j}})=0$, $s({{x}_{i}},{{x}_{j}})=1$ indicates that the two objects are completely repeated; when $d({{x}_{i}},{{x}_{j}})\to \infty $, $s({{x}_{i}},{{x}_{j}})=1$ indicates that the two objects are completely unrelated.
Assuming $n$ objects ${{x}_{i}}{{({{x}_{i1}},\cdots ,{{x}_{im}})}^{T}}$ in the $m$-dimensional feature space in relation $R$, the similarity matrix between objects is expressed as Equation(5).
In Equation(4), any two objects in relation ${{s}_{ij}}=s({{x}_{i}},{{x}_{j}})$, the entropy metric between them is defined as Equation(6).
Equation(6) shows that entropy measures the nature of the similarity between two objects.
(1) When $s({{x}_{i}},{{x}_{j}})=1$, $d({{x}_{i}},{{x}_{j}})=0$ or when $s({{x}_{i}},{{x}_{j}})\to 0$, $d({{x}_{i}},{{x}_{j}})\to \infty $, ${{H}_{ij}}=0$, that is, the maximum or minimum similarity between two objects, the entropy is the smallest.
(2) When $s({{x}_{i}},{{x}_{j}})=0.5$, $d({{x}_{i}},{{x}_{j}})=\sigma \ln 2$, ${{H}_{ij}}=1$, the entropy is the largest. If all objects in the feature space are considered, the overall entropy can be expressed as Equation(7).
Where ${{H}_{ij}}$ represents the attribute entropy of a feature. Let the attribute set of the $m$-dimensional space be $F=\{{{X}_{1}},\cdots ,{{X}_{m}}\}$, then the importance of the attribute ${{X}_{k}}$ can be measured by the increase of the total entropy after deleting the attribute ${{X}_{k}}$ in the feature set $F$.
Where $(F-{{X}_{k}})$ indicates that the attribute ${{X}_{k}}$ is deleted from the attribute set $F$, and ${{E}_{H}}(\cdot )$ indicates the total entropy measure value before and after the attribute ${{X}_{k}}$ is deleted. In order to make the entropy in the attribute subspace of different dimensions comparable, the inter-record similarity should be calculated after the dimension normalization pre-processing.
After deleting attribute ${{X}_{i}}$, if the overall entropy is increased, $\operatorname{Im}p({{X}_{k}})\ge 0$, it indicates that the attribute is very distinguishable and helps to distinguish the cluster structure, and the attribute should be retained. Conversely, if attribute ${{X}_{i}}$ is deleted, the overall entropy is reduced by $\operatorname{Im}p({{X}_{k}})\le 0$. This indicates that the attribute is an unrelated attribute and can be deleted. When $\operatorname{Im}p({{X}_{k}})=1$, the attribute ${{X}_{i}}$ is deleted, which has the unique role of distinguishing clusters and should be retained. When $\operatorname{Im}p({{X}_{k}})=-1$, the deleted attribute ${{X}_{i}}$ is completely confused, difficult to cluster, and should be deleted. After calculating $\operatorname{Im}p\text{(}{{X}_{k}}\text{)}$, the importance of attributes can be measured and sorted according to values, and important attributes are selected to remove unimportant attributes, thereby reducing the dimension of the attributes.
After the data is grouped, it is necessary to detect similar duplicate records of the small data sets of each group. Before cluster detection, the records in the data set are first mapped to points in the ${n}'$-dimensional space.Geometrically, if the two points are close together, they are two similar records in the data set. Calculation of the similarity between the two records evolves into the calculation of the distance between the two points.Considering the accuracy and time of detection, according to the idea based on q-gram algorithm [8], all records in the grouped small data set are mapped to a one-dimensional space after attribute reduction by 2-gram. A large number of records appear as different points in a $n$-dimensional space, and each point has $n$ dimensions.Assume that relationship $R$ contains all the records, and the number of attributes of $R$is recordedas $dom(R)$. The set of all strings of attribute $j$ is recordedas $R\left[ j \right]$. The jth attribute value of each record recorded as $r$. $r$ is recorded as $r\left[ j \right]$. $Gq\left[ r \right]$ representsa multipleset of all attribute q-grams of record $r$. The N-gram hierarchical spatial similarity measure [9] is used to project the records into points in space. Then, after the two records ${{r}_{1}}$,${{r}_{2}}$are mapped into points in the $n$-dimensional ${{\Omega }_{q}}$ space, the similarity between the two can be calculated by Equation(9).
Among them, $coo{{d}_{i}}\left( {{r}_{1}} \right)$ represents all attributes of record ${{r}_{1}}$, and $coo{{d}_{i}}\left( {{r}_{2}} \right)$ represents all attributes of record ${{r}_{2}}$. $\max \left( \cdot \right)$ represents the maximum approximation, and $\min \left( \cdot \right)$ represents the minimum approximation.
The above process reduces the dimension of the spatial point, but the dimension is still high for the data in the database. For the characteristics of high-dimensional data, the support vector machine algorithm [10] is used in each small data set to detect similar duplicate records.
Assume that $H$ represents a sample randomly selected in each group, and all training samples are divided into two categories by finding an optimal classification hyperplane.
Where $b$ represents the bias term, $\omega$ represents the adjustable weight vector, ${{\psi }^{.}}\left( {{x}_{i}} \right)$ represents the vector in the sample set, and ${{y}_{i}}$ represents the algebraic distance. For a class hyperplane, parameter $\left( \omega ,b \right)$ is not uniquely determined. There must be a pair of $\left( \omega ,b \right)$ guarantees (10), and the minimum distance between ${{\psi }^{.}}\left( {{x}_{i}} \right)$ and the class hyperplaneis $1/\left\| \omega \right\|$, allowing some misclassified points to exist, so that Equation(10) becomes Equation(11).
Where ${{\zeta }_{i}}$ represents a negative relaxation variable when ${{\zeta }_{i}}=0$ is satisfied. It indicates complete linear separability.
For a linear indivisible problem, you need to turn it into an optimization problem and then find the optimal classification hyperplane. By introducing a penalty factor of $C>0$, Equation(12) is obtained.
Introducing the Lagrangian operator ${{\alpha }_{i}}$to convert the above equation to Equation(13).
The classification discriminant function of the support vector machine is given by Equation(14).
$K\left( {{x}_{i}},x \right)$ represents a Gaussian kernel function.
The similar discrepancy record is detected using the classification discriminant function given by Equation(15).
Where $sF$ is the change category of the value of the duplicate record attribute.
2.2. IQPSO Algorithm for Supporting Similar Repetitive Record Detection of Support Vector Machines
When the values of the support vector machine parameters $C$ and $\omega $ are different, the classification performance of the support vector machine is very different. This shows that the merits of the parameters $C$ and $\omega $ directly determine the classification performance of the support vector machine, and the IQPSO algorithm optimizes the selection of the support vector machine parameters. According to the diversity of the population in the evolution of the population, the adaptive adjustment strategy [11] is used, taking into account the diversity and convergence speed of the population, and preventing the quantum particle swarm algorithm from falling into the local optimal value as much as possible. According to these methods, the purpose of improving the search capability and performance of the quantum particle swarm optimization algorithmis achieved. The measure of population diversity is calculated by calculating the sum of Euclidean distances between particles or the sum of Euclidean distances from all particles to the center. The following measurement methods are used.
Among them, $S\left( t \right)$ refers to the entire group. ${{n}_{s}}$ is the size of the entire group, $L$ is the longest diagonal length of the search space. ${{n}_{x}}$ is the dimension of the problem solved, ${{x}_{i,{j}'}}\left( t \right)$ is the value of the ${j}'$th dimension of the tthparticle. $\overline{{{x}_{{{j}^{'}}}}\left( t \right)}$is the ${j}'$th average of all particles.
In general, populations that are randomly initialized will be relatively high during the initial stages of population evolution. As evolution progresses, particles will continue to aggregate and diversity will gradually decrease, which will result in enhanced local search capabilities of the algorithm and weaken global search capabilities. For the early and middle stages of evolution, the reduction in diversity is necessary for effective searching. However, in the middle and late stages, especially in the later stages, when the diversity is reduced to a very small extent, the particles are concentrated in a small area, which may cause the whole population to fall into local extreme points. In order to overcome the loss of group diversity, a simple and effective method is to combine the advantages of other evolutionary algorithms with the quantum behavior particle swarm algorithm. Cross-operation and mutation operations [12] were introduced, and different adaptive adjustment strategies were adopted according to the diversity of groups in the evolution process.
When the population is more or less equal to the threshold ${{d}_{l}}$ during evolution, the two particles with the lowest fitness value are generated by the current optimal position $Pb{{t}_{w}}$ and the current optimal velocity of a randomly selected particle $Pb{{t}_{\tau }}$ is used to generate two new individuals.
$\tau$ is a random number between $\left[ 0,1 \right]$. Compare the fitness values of $x_{new}^{1}$ and $x_{new}^{2}$ and choose the better one and continue to compare with ${{x}_{w}}$. If the fitness value is better than ${{x}_{w}}$, replace the worst particle with the new one. This allows the group to move closer to the optimal solution and speed up the convergence.
When the group evolves, the diversity will continue to decrease. When 1 is less than a certain threshold 2, certain measures need to be taken to maintain the diversity of the group, and to avoid falling into the local optimum point as much as possible. Muting the particles to jump to a new location is a common way to improve the diversity of the population [13]. There are usually two kinds of variation: Cauchy variation and Gaussian variation. Because the two wings are almost parallel to the axis of abscissa, the Cauchy variation is more likely to generate random numbers farther from the origin, which makes it easier for the population to escape from the local optimum. Use the Cauchy variation to generate random numbers. The probability density function of the Cauchy mutation is defined as Equation(18).
Where $a$ is the scale parameter, and its distribution function is defined as Equation(19).
When $d\left( S \right)<{{d}_{I}}$, the individual optimal value of a particle has not improved in the past iterations. It can be assumed that it may be stuck in a local extremum. At this point, you need to jump to a new point, enhance its searchability, and perform a Cauchy variation on its position and its individual optimal value. Generate new individuals for each particle selected in the following way.
$C\left( 0,1 \right)$ represents the Cauchy random number and $\eta$ represents the scale parameter.
The fitness of individual particles plays a key role in the process of database repeat recording and detection. Follow these guidelines: The particles with the highest classification accuracy and less repeated records are selected as the quality individuals, then the adaptability is better. The fitness function can be designed as Equation(21).
$SVM$ indicates the classification accuracy of the support vector machine. $F\underline{{}}s$ indicates the number of duplicate records currently selected. The precision weights ${{W}_{a}}$ and $\left( 1-{{W}_{a}} \right)$ respectively indicate the importance of the classification performance of the support vector machine and the size of the selected number of repeated records in the fitness. The optimal parameters of the support vector machine can be obtained by designing the fitness function.
Construct a duplicate record detection model based on the optimal parameter training classifier.
$\eta $ indicates the number of iterations.
3. Experimental simulation
In order to account for the comprehensive effectiveness of the database repeat record detection method based on the improved quantum particle swarm algorithm, simulation experiments were carried out in a CPU P42.8 GMHZ, RAM 2GB, and operating system Windows 2000 environment. Using SQL Server 2005 as the database software, the data source of a website's talent database, a total of 80,000 records each consisting of 4 segments was manually added with 500 duplicate records and the records were divided into training and test sets. Under the same experimental conditions, the big data similar repeated record detection algorithm based on the MapReduce model and the improved algorithm of high-dimensional similar repeated record detection based on the R-tree index were selected for comparison experiments. The evaluation index selects the commonly used precision and recall rate.
The Precision Ratio of the record indicates the proportion of the correct similar duplicate records detected in all detected similar duplicate records. The recall ratio (Recall Ratio) of the record represents the proportion of the actual duplicate similar records recorded in the database for the correct similar duplicate records. Let $C$ denote the actual similar duplicate records in the database. $F$indicates the correct similar duplicate record detected. $T$indicates the similar repeated records detected, and the precision ratio ${{R}_{P}}$ and the recall rate are calculated by Equations(24)-(25).
Figure 1 and Figure 2 show the change of the precision and recall rate of different detection methods with the number of records. In order to simplify the description,the big data similar repeated record detection algorithm based on the MapReduce model and the improved algorithm of high-dimensional similar repeated record detection based on R-tree index are respectively denoted as B, F and H.
Figure 1.
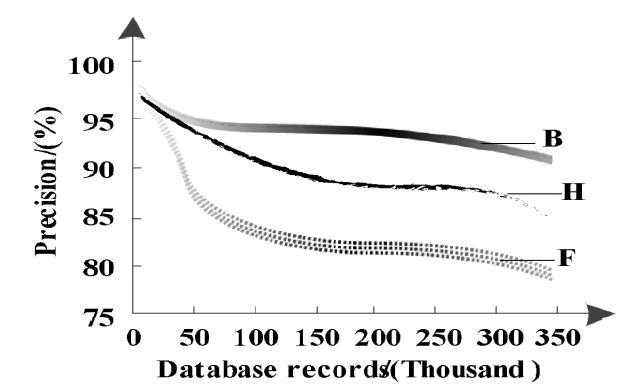
Figure 1.
The variation of the precision of different methods with the number of records
Figure 2.
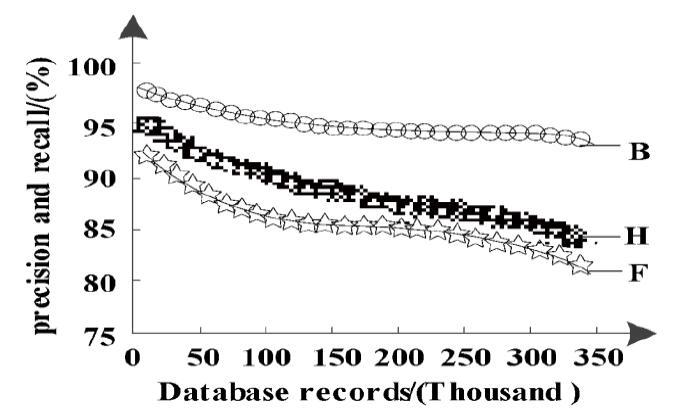
Figure 2.
Changes in the recall rate of different methods with the number of records
As can be seen from Figure 1 and Figure 2, when the number of database records is 50,000, the precision of the proposed method is 95.5%. The precision of the big data similar duplicate record detection algorithm based on the MapReduce model is 93.2%. The accuracy of the improved algorithm for high-dimensional similar duplicate records detection based on the R-tree index is 87%. When the number of records is relatively small, the performance of the three detection methods is not very different. However, with the increase of records, the performance of the big data algorithm based on the MapReduce model and the improved algorithm of high-dimensional based on the R-tree index is much lower. The big data algorithm based on the MapReduce model has a great relationship with the Map function and Reduce function setting, resulting in a low actual recall rate and precision. In contrast, the proposed method is superior to the big data algorithm based on the MapReduce model and the high-dimensional algorithm based on the R-tree index. This is mainly because the IQPSO algorithm optimizes the parameters of the support vector machine, obtains the optimal parameters of the support vector machine, and builds the repeated record detection model based on the obtained optimal parameter training classifier, which improves the detection accuracy.
The proposed method, the big data similar algorithm based on the MapReduce model and the improved algorithm of high-dimensional based on the R-tree index are used for repeated record detection. The required running time (ms) comparison results are shown in Figure 3.
Figure 3.
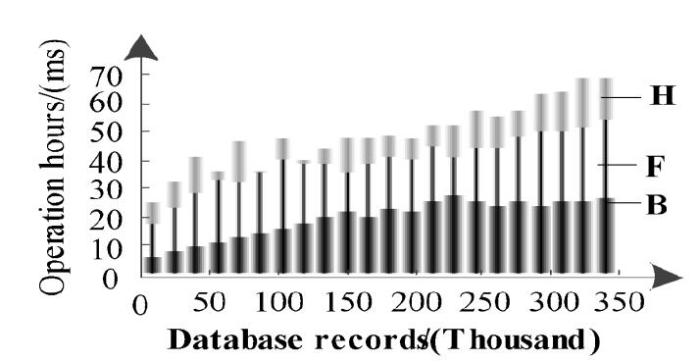
Figure 3.
Comparison of running time of different methods
It can be seen from Fig. 3 that with the increase of the number of records, the proposed method, the big data similar repeated record detection algorithm based on the MapReduce model and the improved algorithm of high-dimensional similar repeated record detection algorithm based on R-tree index increase. However, the detection time of the proposed method is shorter. The comparison results show that the proposed method effectively improves the efficiency of database duplicate record detection, and satisfies the real-time requirements of large-scale database duplicate record detection.
4. Conclusions
The detection methods of similar duplicate records existing at present are studied, and the existing methods for detecting similar duplicate records were studied. The main work was summarized as follows.
(1) Focus on the detection methods of similar duplicate records. The method of similarity measurement between records was studied, and the related algorithms of similar repeated record detection were proposed. The method of grouping clustering similar duplicate records based on the entropy feature was proposed. By constructing an entropy metric in terms of the similarity between objects, the weight of each attribute in the original data set was evaluated, and the key feature set was selected. According to the key attributes, the data was divided into disjoint small data sets, and the similar repeated records were detected by the support vector machine algorithm in each small data set.
(2) The performance of the support vector machine classifier was affected by the repeated record data and parameter settings input during training, and two factors needed to be optimized at the same time. The quantum particle swarm optimization algorithm had good optimization ability and had the ability to synchronously optimize the repeated record data and parameter estimation. The IQPSO algorithm was used to optimize the parameters of the support vector machine, and the optimized support vector machine parameters were used in the process of repeated record detection, which effectively improved the accuracy of similar duplicate record detection.
The proposed method improved the quantum behavior particle swarm optimization algorithm. Compared with the original quantum behavior particle swarm optimization algorithm, the performance made great progress. However, there was still the possibility of falling into local optimums. Further improvements to the quantum behavior particle swarm optimization algorithm can be considered from other perspectives.
Reference
“Progressive Duplicate Detection,”
“Duplicate Literature Detection for Cross-Library Search,”
DOI:10.1515/cait-2016-0028
URL
[Cited within: 1]

The proliferation of online digital libraries offers users a great opportunity to search their desired literatures on Web. Cross-library search applications can help users search more literature information from multiple digital libraries. Duplicate literatures detection is always a necessary step when merging the search results from multiple digital libraries due to heterogeneity and autonomy of digital libraries. To this end, this paper proposes a holistic solution which includes achieving automatic training set, holistic attribute mapping, and weight of attribute training. The experiments on real digital libraries show that the proposed solution is highly effective.
“DARE: A Deduplication-Aware Resemblance Detection and Elimination Scheme for Data Reduction with Low Overheads,”
DOI:10.1109/TC.2015.2456015
URL
[Cited within: 1]
Data reduction has become increasingly important in storage systems due to the explosive growth of digital data in the world that has ushered in the big data era. One of the main challenges facing large-scale data reduction is how to maximally detect and eliminate redundancy at very low overheads. In this paper, we present DARE, a low-overhead deduplication-aware resemblance detection and elimination scheme that effectively exploits existing duplicate-adjacency information for highly efficient resemblance detection in data deduplication based backup/archiving storage systems. The main idea behind DARE is to employ a scheme, call Duplicate-Adjacency based Resemblance Detection (DupAdj), by considering any two data chunks to be similar (i.e., candidates for delta compression) if their respective adjacent data chunks are duplicate in a deduplication system, and then further enhance the resemblance detection efficiency by an improved super-feature approach. Our experimental results based on real-world and synthetic backup datasets show that DARE only consumes about 1/4 and 1/2 respectively of the computation and indexing overheads required by the traditional super-feature approaches while detecting 2-10 percent more redundancy and achieving a higher throughput, by exploiting existing duplicate-adjacency information for resemblance detection and finding the weet spot for the super-feature approach.
“Using Probabilistic Record Linkage of Structured and Unstructured Data to Identify Duplicate Cases in Spontaneous Adverse Event Reporting Systems,”
DOI:10.1007/s40264-017-0523-4
URL
[Cited within: 1]
Duplicate case reports in spontaneous adverse event reporting systems pose a challenge for medical reviewers to efficiently perform individual and aggregate safety analyses. Duplicate cases can bias d
“Fractal Cross-Layer Service with Integration and Interaction in Internet of Things,”
“A Review of Visual Moving Target Tracking,”
“Cost-Sensitive Linguistic Fuzzy Rule based Classification Systems under the MapReduce Framework for Imbalanced Big Data,”
DOI:10.1016/j.fss.2014.01.015
URL
[Cited within: 1]
Classification with big data has become one of the latest trends when talking about learning from the available information. The data growth in the last years has rocketed the interest in effectively acquiring knowledge to analyze and predict trends. The variety and veracity that are related to big data introduce a degree of uncertainty that has to be handled in addition to the volume and velocity requirements. This data usually also presents what is known as the problem of classification with imbalanced datasets, a class distribution where the most important concepts to be learned are presented by a negligible number of examples in relation to the number of examples from the other classes. In order to adequately deal with imbalanced big data we propose the Chi-FRBCS-BigDataCS algorithm, a fuzzy rule based classification system that is able to deal with the uncertainly that is introduced in large volumes of data without disregarding the learning in the underrepresented class. The method uses the MapReduce framework to distribute the computational operations of the fuzzy model while it includes cost-sensitive learning techniques in its design to address the imbalance that is present in the data. The good performance of this approach is supported by the experimental analysis that is carried out over twenty-four imbalanced big data cases of study. The results obtained show that the proposal is able to handle these problems obtaining competitive results both in the classification performance of the model and the time needed for the computation.
“Similarity Detection in Biological Sequences using Parameterized Matching and Q-gram, ”
in
“An Efficient Matrix Factorization based Low-Rank Representation for Subspace Clustering,”
DOI:10.1016/j.patcog.2012.06.011
URL
[Cited within: 1]
Summary: In recent years, robust subspace clustering is an important unsupervised clustering problem in machine learning and computer vision communities. The recently proposed spectral clustering based approach, called low-rank representation (LRR), yields an optimal solution for the case of independent subspaces and partially corrupted data. However, it has to be solved iteratively and involves singular value decomposition (SVD) at each iteration, and then suffers from high computation cost of multiple SVDs. In this paper, we propose an efficient matrix tri-factorization (MTF) approach with a positive semidefinite (PSD) constraint to approximate the original nuclear norm minimization (NNM) problem and mitigate the computation cost of performing SVDs. Specially, we introduce a matrix tri-factorization idea into the original low-rank representation framework, and then convert it into a small scale matrix nuclear norm minimization problem. Finally, we establish an alternating direction method (ADM) based algorithm to efficiently solve the proposed problem. Experimental results on a variety of synthetic and real-world data sets validate the efficiency, robustness and effectiveness of the proposed MTF approach comparing with the state-of-the-art algorithms.
“Far Efficient K-Means Clustering Algorithm,”
in
“Adaptive Duplicate Detection using Learnable String Similarity Measures,”
in
DOI:10.1145/956750.956759
URL
[Cited within: 1]
The problem of identifying approximately duplicate records in databases is an essential step for data cleaning and data integration processes. Most existing approaches have relied on generic or manually tuned distance metrics for estimating the similarity of potential duplicates. In this paper, we present a framework for improving duplicate detection using trainable measures of textual similarity. We propose to employ learnable text distance functions for each database field, and show that such measures are capable of adapting to the specific notion of similarity that is appropriate for the field's domain. We present two learnable text similarity measures suitable for this task: an extended variant of learnable string edit distance, and a novel vector-space based measure that employs a Support Vector Machine (SVM) for training. Experimental results on a range of datasets show that our framework can improve duplicate detection accuracy over traditional techniques.
“Identifying and Removing Duplicate Records from Systematic Review Searches,”
DOI:10.3163/1536-5050.103.4.004
URL
PMID:26512216
[Cited within: 1]
INTRODUCTIONSystematic reviews continue to gain prevalence in health care primarily because they...
“Distributional Fractal Creating Algorithm in Parallel Environment,”

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}