Jinli Che is a Master's student at Army Engineering University. His main research are as are knowledge graphs and natural language processing. Liwei Tang is a professor at Army Engineering University. He obtained his Master's degree and doctorate from Tianjin University. He has published technical articles in several refereed journals and international conferences. His main research areas are data processing and machine learning. Shijie Deng is a lecturer at Army Engineering University. He obtained his Master's degree and doctorate from Army Engineering University. His main research areas are machine learning and natural language processing. Xujun Su is a lecturer at Army Engineering University. He obtained his Master's degree from Army Engineering University. His main research areas are big data and knowledge graphs.
Abstract
As an effective model for processing time series data, the recurrent neural network has been widely used in the problem of sequence tagging tasks. In order to solve the typical sequence tagging task of Chinese word segmentation, in this paper we propose an improved bidirectional gated recurrent unit conditional random field (BI-GRU-CRF) model based on the gated recurrent unit (GRU) neural network. This network is more easily trained than the LSTM neural network. This method can not only effectively utilize text information in two directions through bidirectional gated recurrent units, but also obtain the globally optimal tagging sequence as a result by considering the correlation between neighbor tags through the conditional random field. In this paper, experiments are carried out on the common evaluation set (PKU, MSRA, CTB) with the four-tag-set and six-tag-set respectively. The results show that the BI-GRU-CRF model has high performance in Chinese word segmentation, and the six-tag-set can improve the performance of the network.
Keywords: recurrent neural network;
BI-GRU-CRF;
Chinese word segmentation;
sequence tagging
Jinli Che, Liwei Tang, Shijie Deng, Xujun Su. Chinese Word Segmentation based on Bidirectional GRU-CRF Model. International Journal of Performability Engineering, 2018, 14(12): 3066-3075 doi:10.23940/ijpe.18.12.p16.30663075
1. Introduction
As an important basic task in Natural Language Processing (NLP), Chinese word segmentation plays an irreplaceable role in many fields, such as text classification, machine translation, intelligent answers, and so on. The accuracy of segmentation tasks has a direct impact on the performance of subsequent tasks. However, Chinese is different from other languages such as English. It is written continuously by Chinese characters, and there is no marked distinction between words such as the space in English. The division of words is rather vague and brings great difficulty to Chinese word segmentation.
With the development of the Bakeoff (an international competition of NLP), many researchers have been widely involved. It has caused Chinese word segmentation technology to become the focus of research and has made great progress[1]. At present, the main methods include methods based on dictionary, methods based on statistical model, and methods based on deep neural network.
The method based on dictionary, also known as methods based on string matching or methods based on mechanical segmentation, is an earlier method for segmentation. It mainly compares the input sentences with the manually constructed dictionaries, identifies the words contained in the dictionary, and then achieves the segmentation of sentences. According to the scanning method, it includes bidirectional scanning, forward matching, and inverse matching [2]. The advantages of the method are strong pertinence, and the accuracy of segmentation is high facing words contained in dictionaries. However, the shortcomings are transparent. This method cannot deal with the problem of unknown words and word ambiguity effectively. It also has poor adaptability to different fields, and the cost of manual maintenance of dictionaries is high.
This method based on statistical model usually takes Chinese word segmentation as a sequence tagging problem. It solves the problem of identifying unknown words and has gradually become the mainstream method. Xue[3] et al. first proposed tagging the corpus into the four tag set of (B, M, E, S) and realized the segmentation task based on the maximum entropy(ME) model. Liu [4]realized Chinese lexical analysis based on the hidden Markov model(HMM) model. Qianand others [5] researched the techniques of word segmentation in ancient and modern Chinese, and they realized the segmentation of Chu Ci based on the HMM model. Collobert[6] implemented segmentation tasks with subclassification conditional random field(CRF).Zhao[7] provided more tag selection based on the CRF model to improve the segmentation effect. However, these methods based on statistical model require a large number of statistical features. The performance of word segmentation network relies seriously on the quality of the artificial design features. With an increase in the number of features, the training is easy to overfit, the generalization ability of modelis poor, and the training time is increasing.
In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results.
The prediction of each word’s tag is independent and does not consider the dependence between tags in these word segmentation methods based on the deep neural network. Therefore, in this paper, we add a CRF layer after the bidirectional GRU network to use sentence level tag information. This method can not only make use of the bidirectional GRU network to efficiently use both past and future input features but also use the CRF layer to achieve better segmentation performance. Finally, the experimental results show that the BI-GRU-CRF model has better segmentation performance than the CRF, GRU, and BI-GRU model.
2. Models
Inspired by the paper [12], we abstract Chinese word segmentation task as a character-based sequence tagging task. That is to say, we use the neural network model to predict the tags for each input character. The model will tag every character as one of "BMES" set. On the basis of the Chinese word segmentation model proposed in paper [12], in this paper, the network unit is replaced by the gated recurrent unit(GRU) which can deal with the long distance information, and the CRF layer is added after the output layer to form a bidirectional gated recurrent unit conditional random field (BI-GRU-CRF) model. We predict the whole tag sequence by using the sentence level tag information between the tags.
2.1. Traditional RNN Network
The recurrent neural network(RNN) is different from the convolutional neural network (CNN). There are connections between hidden layer nodes of RNN to add the previous state of the hidden layer nodes to the calculation of the current state of the hidden layer nodes. This structure makes full use of historical information, and its basic structure is shown in Figure 1. The structure’s ability to make use of context information makes the RNN network widely applied in the natural language processing field.
InFigure 1, x(t) is the input.For example, it represents the word embedding of the tth input Chinese character in word segmentation. state (t) is the hidden state output of the RNN node at time t, and its computation depends on the state of the previous state state (t-1) and the current input x(t):
Where W is the connection weight matrix of the input layer to the hidden layer, U is the connection weight matrix of the hidden layer at the previous time to the current time, B is the bias parameter matrix, and the tanh is the activation function.
o(t) is the output, such as the probability of the tth prediction tag in word segmentation, and its computation relies on the state of the current node.
Where V is the connection weight matrix between hidden layer and output layer, and soft max is used as a classification function. The parameters of the RNN network are shared in the training in order to reduce training parameters, that is, theW,U, B, and V connection weights in the previous text are the same in the calculation at every state.
2.2. GRU Cell
In theory, the RNN network can use the hidden layer state state (t) to capture all the preceding input information, but the reality is not so perfect. The related research of Bengio[19] and Pascanu[20] shows that the hidden layer nodes are only simple to use tanh functions in the processing of long distance information in the traditional RNN network, which makes the training easy to fall into the problem of gradient disappearance and gradient explosion.
Therefore, LSTM[21] and GRU[15] cells have been proposed to replace tanh activation functions in traditional RNN networks in order to solve these problems. They are all the cells based on the gates, in which LSTM has the input gate, the forget gate, and the output gate.GRU is an improved model that is more concise and efficient than LSTM. It only has thereset gate and the update gate, where the update gate combines the input gate and the forget gate in the LSTM. The internal structure ofthe GRU cell is shown in Figure 2.
Where ${{\mathbf{z}}_{t}}$ represents the update gate, $\widetilde{{{\mathbf{h}}_{t}}}$ is the candidate value for the current hidden node, ${{\mathbf{h}}_{t\text{-1}}}$ is the activation value for the previous hidden node, and ${{\mathbf{h}}_{t}}$ is the activation value for the current hidden node. It can be seen from the formula that the update gate controls how much historical information ${{\mathbf{h}}_{t\text{-1}}}$ is forgotten and how much current information $\widetilde{{{\mathbf{h}}_{t}}}$ is remembered. The GRU cell can remember more current information and forget more historical information when ${{\mathbf{z}}_{t}}$ is larger. The update gate can be calculated as:
Where ${{\mathbf{x}}_{\mathbf{t}}}$ is the input, $\sigma $ is the logistic sigmoid function, $\phi $ is thetanh activation function, and $\odot $ means multiplication by element. ${{\mathbf{r}}_{t}}$ represents the reset gate, and it can be calculated as:
Wz, Wh,Wr, Uz, Uh, Ur,bz, bh,and br in Equations (4)-(6) are all weights matrices for training. ${{\mathbf{r}}_{t}}$ controls how much input information ${{\mathbf{x}}_{t}}$ and how much historical information ${{\mathbf{h}}_{t\text{-1}}}$ affect $\widetilde{{{\mathbf{h}}_{t}}}$. The larger the ${{\mathbf{r}}_{t}}$, the smaller the influence of ${{\mathbf{x}}_{t}}$ on $\widetilde{{{\mathbf{h}}_{t}}}$, and the greater the influence of ${{\mathbf{h}}_{t\text{-1}}}$ on $\widetilde{{{\mathbf{h}}_{t}}}$. Therefore, the GRU cell has the ability to learn the long distance information through the two gate units of the reset gate and the update gate, which relieves the problem of the gradient disappearance or explosion caused by the traditional RNN network training.
2.3. Bidirectional GRU Network
We need not only the past information of the text sequencebut also the future information of the text sequence when dealing with Chinese word segmentation task. However, the unidirectional RNN network cannot deal with such a problem well. Therefore, the bidirectional RNN network[17] is more suitable for Chinese word segmentation tasks, because it can simultaneously utilize the past and future input features. The structure of the bidirectional GRU network is shown in Figure 3.
We only need to replace the nodes of RNN networks in the two hidden layers of the forward and backward with GRU cells to form a bidirectional GRU(BI-GRU) network. Compared with the unidirectional GRU network, the bidirectional GRU network adds a hidden layer. The text sequence is input into the model in forward and backward two directions, and the two hidden layers are all connected to the output layer. Therefore, the network can simultaneously utilize long distance information in two directions.
2.4. BI-GRU-CRF Model
2.4.1. CRF Network
The relationship between neighbor tags is also important when we predict the final tag sequence in a sequence tagging task. For example, when we predict the tags with the tag of “BMES” tag set, the back of the tag B is impossible to be the tag B. Therefore, we need to judge the final tag result according to the score of the whole tag sequence. As a probability model of sequence prediction, CRF can consider the correlation between neighbor tags to get the global optimal tag sequence as the result. It has been shown that CRFs can produce higher tagging accuracy in general, andits structure is shown in Figure 4.
The BI-GRU-CRF model is to combine the bidirectional GRU network with the CRF layer. It adds the CRF layer after the output layer of the bidirectional GRU network, and the basic structure is shown in Figure 5. The model can effectively utilize the bidirectional GRU network to obtain the past and future information in the input text as the features and predict the whole tag sequence through the CRF layer, so as to achieve the optimal tagging of the text sequence.
In this network model, $\mathbf{x}=\{{{x}_{1}},{{x}_{2}},\cdots ,{{x}_{n}}\}$ represents a given input text sequence, and $\mathbf{y}=\{{{y}_{1}},{{y}_{2}},\cdots ,{{y}_{n}}\}$ represents a sequence of tags for $\mathbf{x}=\{{{x}_{1}},{{x}_{2}},\cdots ,{{x}_{n}}\}$. We can define:
Where ${{\mathbf{P}}_{n\times k}}$ is the output probability matrix of the bidirectional GRU layer, n is the number of Chinese characters, and k is the type of the output tag, that is, ${{\mathbf{P}}_{i,j}}$ is the transition probability that represents the score of the jth tag of the ith word.
In addition, $\mathbf{A}$ is the transition score matrix. ${{\mathbf{A}}_{i,j}}$ denotes the emission probability that represents the score of transition from tag i to tag j, and the conditional probability of the tag sequence $\mathbf{y}$ is:
In this paper, based on the basic Chinese word segmentation model proposed in paper [12], the BI-GRU-CRF network is added to the basic model, and the specific training flow chart is shown in Figure 6.
Figure 6.
The training flow chart of BI-GRU-CRF model
3.1. Training Corpus and Tag Set
In this paper, we use the PKU, MSRA, andCTB6 training corpuses to evaluate our model, and all corpuses have been pre-processed to train corpus and test corpus. We use the (B, M, E, S) tag set, which is commonly used in deep learning, and the (B,B1,B2,M,E,S) tag set, which is a better way to express word information to mark the corpus, and compare the segmentation results. We mark the(B, M, E, S) tag set as 4tag and the (B,B1,B2,M,E,S) tag set as 6tag.
3.2. Word Embedding
According to the training process of the word segmentation model [22], before the text sequence is input to the BI-GRU-CRF model, the text should be transformed into a low dimensional character vector abstracting the features of the word as the input of the network model. All the low dimensional vectors are stored in the dictionary D of the lookup layer. Through this dictionary D, the text sequence can be transformed to the corresponding vector sequence after the lookup layer. It has been shown in paper [23] that word embedding plays a vital role in improving sequence tagging performance.
At present, the most commonly used method of word vector representation is based on deep neural network. The method based on deep neural network can abstruse the features of the Chinese character by multiple hidden layers network and represent each Chinese character as a low dimensional real number vector. Therefore, this method can not only effectively avoid the problem of data sparsity, but also better represent the semantic relations between Chinese characters. In paper [6], Collobert used a method ofvector representation based on a deep neural network language model to deal with various natural language processing tasks. Mikolov had proposed two representations of vectors inpaper[24].One is the continuous bag-of-words (CBOW) model that uses the words around to predict the current word, and the other, called the continuous skip-gram model, is the opposite because it uses the current word to predict the surrounding words.These two methods can all represent similar words in a vector space with smaller angles.
Comparing these language models, we find that the skip-gram model has a better effect in solving the problem of data sparsity. Therefore, we will use the skip-gram model to train word vectors on a large Wikipedia corpus. First, we need to set up a Chinese character dictionary D, where d is the dimension of word vector and N is the number of Chinese characters. The word vector of each Chinese characters is pre-trained through the skip-gram model.In this way, the corresponding Chinese character vector for each Chinese character can be queried in the dictionary, and the text sequence can be transformed into a real number sequence to input into the neural network model for training.
3.3. Dropout
Overfitting occurs when themodel only learns to classify on the training set. It is a common problem in deep neural networks. Over the years, many solutions to overfitting problems have been proposed, among which dropout is a simple and common method. On many tasks, dropout has achieved good results. Dropout works well in practice because it prevents neurons from co-adaptation during training. Its basic principle is to abandon the network node in training according to a certain proportion p and not update its corresponding weight, but all nodes are enabled in the process of prediction.In this paper, we add a dropout layer after all two hidden layers ofthe bidirectional GRU network to improve the performance of the segmentation model.
4. Experiments
4.1. Evaluation Criteria
We do experiments based on the PKU, MSRA, and CTB6 corpus.As for the PKU and MSRA corpuses, we use the 80% training corpuses as the training set, the 10% corpuses as the development set, and the remaining 10% corpuses as thetest set. We divide the CTB6 corpus according to the experience of the predecessors. In addition, a thorough evaluation of the model is essential. Therefore, in order to evaluate the segmentation performance of the model, we use the evaluation criterias defined by SIGHAN: the precision, the recall, and the F1 value. The calculations of these evaluation criteria are as follows:
$P=\frac{\text{Correct number of results in prediction}}{\text{Total number of results in prediction}}\times 100%$
$R=\frac{\text{Correct number of results in prediction}}{\text{Correct number of results in test set}}\times 100%$
$F1=\frac{2\times P\times R}{P+R}\times 100%$
4.2. Experimental Setup
In order to verify the performance of the BI-GRU-CRF Chinese word segmentation model proposed in this paper, five experiments are set up.
Experiment1: We use Chinese language rules to build feature templates and use a training corpus with (B, M, E, S) tag set to train the CRF model based on feature templates. Then, the model is used to segment Chinese words on the test corpus. The experiment was marked as CRF(4tag).
Experiment 2: We use a training corpus with (B, M, E, S) tag set to train the GRU model. Then, the model is used to segment Chinese words on the test corpus. The experiment was marked as GRU(4tag).
Experiment 3: We use a training corpus with (B, M, E, S) tag set to train the BI-GRU model. Then, the model is used to segment Chinese words on the test corpus. The experiment was marked as BI-GRU(4tag).
Experiment 4: We use a training corpus with (B, M, E, S) tag set to train theBI-GRU-CRF model. Then, the model is used to segment Chinese words on the test corpus. The experiment was marked as BI-GRU-CRF(4tag).
Experiment 5: We use a training corpus with (B,B1,B2,M,E,S) tag set to train the BI-GRU-CRF model. Then, the model is used to segment Chinese words on the test corpus. The experiment was marked as BI-GRU-CRF(6tag).
In addition, in the training process of the model, we use the dropout to prevent the overfitting and the clipping gradient to relieve gradient disappearance or gradient explosion. We replace the activation function of the GRU unit output gate with the ReLU function to improve the training performance of the model.
4.3. Hyper-Parameters
Hyper-parameters are some variables that are generally determined by experience and used to determine models. Before training, we need to choose some hyper-parameters that influence the performance of word segmentation significantly. We set the hyper-parameters of the model as listed in Table 1 via experiments based on the BI-GRU-CRF model on the development set of the PKU corpus.
In addition, we find that the larger dimension leads to longer time of model training, and the lower dimension leads to lower model performance. It is a good balance between precision and training speed of word segmentation to set the dimension of hidden layer h =128. As for choosing the dropout rate, a higher probability will result in fewer nodes and a poorer fitting effect. Finally, when we choose the initial learning rate, a lower learning rate will lead to longer training time, and a larger learning rate will lead to over-fitting of the model and affect the performance of word segmentation.
4.4. Results
In this paper, we implement the Chinese word segmentation model based on the BI-GRU-CRF network model and carry out word segmentation experiments on the PKU, MSRA, and CTB6 corpuses. Finally, we compare the model performance with other typical word segmentation models: CRF, GRU, and BI-GRU models. In addition, we carry out the experiments with the four-tag-set and six-tag-set in order to compare the performance of different tagging methods. The final results of the above experiments are shown in Table 2.
Table 2
Table 2.Performance of different word segmentation models
From the results of Table 2, we can see that the Chinese word segmentation of the BI-GRU-CRF model is obviously better than the CRF, GRU, and BI-GRU models on the three evaluation criteria of precision, recall, and F1 value. The model with six-tag-set is better than the model with four-tag-set.
In order to further verify the performance of the BI-GRU-CRF model, we compare this model with some models proposed by previous scholars.Table 3 shows some comparisons between the model performance in this paper and some research results of other scholars in the word segmentation field. All these methods were the best model of Chinese word segmentation at that time. Tseng[25] represents a Chinese word segmentation model based on CRF.Collobert[6] represents a Chinese word segmentation model based on a deep neural network model. Chen[14] represents a LSTM model of two character embedded vectors, and the model mounts a word segmentation dictionary. Yao[23] represents a BI-LSTM model with three BI-LSTM layers.From the results of Table 3, we can see that our model can achieve similar segmentation results without mounting the word segmentation dictionary and stacking the layers of neural network. It is enough to prove the better performance of the BI-GRU-CRF model.
Table 3
Table 3.F 1 Value comparison of BI-GRU-CRF with previous research
In this paper, we propose a BI-GRU-CRF Chinese word segmentation model based on GRU neural network. This model not only inherits the features of the GRU unit that are easy to train, but also can use word information and neighbor tags to segment words. We add the pre-trained characters vectors to carry out word segmentation experiments with the four-tag-set and six-tag-set respectively on PKU, MSRA, and CTB6 corpuses. Then, we compare the model performance with other typical word segmentation models: CRF, GRU, and BI-GRU models, along with some research results of other scholars in the word segmentation field. The experimental results show that the BI-GRU-CRF model has better segmentation performance, and the tagging method of six-tag-set can improve the segmentation performance. Future work includes stacking GRU network layers and mounting word segmentation dictionary to improve segmentation performance, and we will apply this model to specific fields.
Acknowledgments
We would like to thank the reviewers for their valuable comments. This workwas partially funded by the National Natural Science Foundation of China (No.51575523) and the Military Research Foundation of China.
During the last decade,especially since the First International Chinese Word Segmentation Bakeoff was held in July 2003,the study in automatic Chinese word segmentation has been greatly improved.Those improvements could be summarized as following:(1) on the computation sense Chinese words in real text have been well-defined by "segmentation guidelines + lexicon + segmented corpus";(2) practical results show that performance of statistic segmentation systems outperforms that of handcrafted rule-based systems;(3) the evaluation in terms of Bakeoff data shows that the accuracy drop caused by outof-vocabulary(OOV) words is at least five times greater than that of segmentation ambiguities;(4) the better performance of OOV recognition the higher accuracy of the segmentation system in whole,and the accuracy of statistic segmentation systems with character-based tagging approach outperforms any other word-based system.
G.H.Feng and W.Zhen, “
Review of Chinese Automatic Word Segmentation
,” Science Library and Information Service, Vol. 55, No. 2, pp. 41-45, January 2011
ABSTRACT In this paper we present Chinese word segmentation algorithms based on the socalled LMR tagging. Our LMR taggers are implemented with the Maximum Entropy Markov Model and we then use Transformation-Based Learning to combine the results of the two LMR taggers that scan the input in opposite directions.
Q.Liu, H.PZhang, H.K.Yu, X.Q.Cheng, “
Chinese Lexical Analysis Using Cascaded Hidden Markov Model
,” Journal of Computer Research and Development, Vol.41, No. 8, pp. 1421-1429, August 2004
This paper presents an approach for Chinese lexical analysis using cascaded hidden Markov model (CHMM), which aims to incorporate Chinese word segmentation, part-of-speech tagging, disambiguation and unknown words recognition into an integrated theoretical frame. A class-based HMM is applied in word segmentation, and in this model, unknown words are treated in the same way as common words listed in the lexicon. Unknown words are recognized with reliability on roles sequence tagged using Viterbi algorithm in roles HMM. As for disambiguation, the authors bring forth an n-shortest-path strategy that, in the early stage, reserves the top N segmentation results as candidates and covers more ambiguity. Various experiments show that each level in the CHMM contributes to Chinese lexical analysis. A CHMM-based system ICTCLAS is accomplished. The system ranked top in the official open evaluation, which was held by the 973 project in 2002. And ICTCLAS achieved 2 first ranks and 1 second rank in the first international word segmentation bakeoff held by SIGHAN (the ACL Special Interest Group on Chinese Language Processing) in 2003. It indicates that ICTCLAS is one of the best Chinese lexical analyzers. In a word, CHMM is effective for Chinese lexical analysis.
Z.Y.Qian, J.Z.Zhou, G.P.Tong, X.N.Sun, “
Research on Automatic Word Segmentation and POS Tagging For Chu Ci b Based on HMM
,” Library and Information Service, Vol. 58, No. 4, pp. 105-110, February 2014
We describe a single convolutional neural network architecture that, given a sentence, outputs a host of language processing predictions: part-of-speech tags, chunks, named entity tags, semantic roles, semantically similar words and the likelihood that the sentence makes sense (grammatically and semantically) using a language model. The entire network is trained jointly on all these tasks using weight-sharing, an instance of multitask learning. All the tasks use labeled data except the language model which is learnt from unlabeled text and represents a novel form of semi-supervised learning for the shared tasks. We show how both multitask learning and semi-supervised learning improve the generalization of the shared tasks, resulting in state-of-the-art-performance.
H.Zhao, C.N.Huang, M.Li, B.L.Lu, “
Effective Tag Set Selection in Chinese Word Segmentation via Conditional Random Field Modeling
,” in Proceedings of the 20th Pacific Asia Conference on Language Information and Computation, pp. 87-94, Wuhan, China,November 2006
Deep learning has recently achieved breakthrough progress in speech recognition and image recognition.With the advent of big data era,deep convolutional neural networks with more hidden layers and more complex architectures have more powerful ability of feature learning and feature representation.Convolutional neural network models trained by deep learning algorithm have attained remarkable performance in many large scale recognition tasks of computer vision since they are presented.In this paper,the arising and development of deep learning and convolutional neural network are briefly introduced,with emphasis on the basic structure of convolutional neural network as well as feature extraction using convolution and pooling operations.The current research status and trend of convolutional neural networks based on deep learning and their applications in computer vision are reviewed,such as image classification,object detection,pose estimation,image segmentation and face detection etc.Some related works are introduced from the following three aspects,i.e.,construction of typical network structures,training methods and performance.Finally,some existing problems in the present research are briefly summarized and discussed and some possible new directions for future development are prospected.
X.F.Xi and G.D.Zhou,“
A Survey on Deep Learning for Natural Language Processing
,” ACTA Automatic Sinica, Vol. 42, No. 10, pp. 1445-1465, October 2016
Recently, deep learning has made significant development in the fields of image and voice processing. However,there is no major breakthrough in natural language processing task which belongs to the same category of human cognition.In this paper, firstly the basic concepts of deep learning are introduced, such as application motivation, primary task and basic framework. Secondly, in terms of both data representation and learning model, this paper focuses on the current research progress and application strategies of deep learning for natural language processing, and further describes the current deep learning platforms and tools. Finally, the future development difficulties and suggestions for possible extensions are also discussed.
Y.Bengio, R.Ducharme, P.Vincent, andC.Jauvin, “
A Neural Probabilistic Language Model
,” Journal of Machine Learning Research, Vol. 3, No. 6, pp. 1137-1155, March 2003
A central goal of statistical language modeling is to learn the joint probability function of sequences of words in a language. This is intrinsically difficult because of the curse of dimensionality : a word sequence on which the model will be tested is likely to be different from all the word sequences seen during training. Traditional but very successful approaches based on n-grams obtain generalization by concatenating very short overlapping sequences seen in the training set. We propose to fight the curse of dimensionality by learning a distributed representation for words which allows each training sentence to inform the model about an exponential number of semantically neighboring sentences. Generalization is obtained because a sequence of words that has never been seen before gets high probability if it is made of words that are similar (in the sense of having a nearby representation) to words forming an already seen sentence. Training such large models (with millions of parameters) within a reasonable time is itself a significant challenge. We report on several methods to speed-up both training and probability computation, as well as comparative experiments to evaluate the improvements brought by these techniques. We finally describe the incorporation of this new language model into a state-of-the-art speech recognizer of conversational speech.
X.Q.Zheng, H.Y.Chen, T.Y.Xu, “
Deep Learning for Chinese Word Segmentation and POS Tagging
,” in Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pp. 647-657,Seattle, Washington,USA, October 2013
Gated Recursive Neural Network for Chinese Word Segmentation
,” in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, pp. 567-572, Beijing, China, July 2015
Abstract: In this paper, we propose a novel neural network model called RNN Encoder-Decoder that consists of two recurrent neural networks (RNN). One RNN encodes a sequence of symbols into a fixed-length vector representation, and the other decodes the representation into another sequence of symbols. The encoder and decoder of the proposed model are jointly trained to maximize the conditional probability of a target sequence given a source sequence. The performance of a statistical machine translation system is empirically found to improve by using the conditional probabilities of phrase pairs computed by the RNN Encoder-Decoder as an additional feature in the existing log-linear model. Qualitatively, we show that the proposed model learns a semantically and syntactically meaningful representation of linguistic phrases.
R.Jozefowicz, W.Zaremba, I.Sutskever, “
An Empirical Exploration of Recurrent Network Architectures
,”in Proceedings of the 32nd International Conference on Machine Learning, pp. 2342-2350, Lille, France, July 2015
The Recurrent Neural Network (RNN) is an extremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train. While wildly successful in practice, the LSTM’s architecture appears to be ad-hoc so it is not clear if it is optimal, and the significance of its individual components is unclear. In this work, we aim to determine whether the LSTM architecture is optimal or whether much better architectures exist. We conducted a thorough architecture search where we evaluated over ten thousand different RNN architectures, and identified an architecture that outperforms both the LSTM and the recently-introduced Gated Recurrent Unit (GRU) on some but not all tasks. We found that adding a bias of 1 to the LSTM’s forget gate closes the gap between the LSTM and the GRU.
A.Graves and J.Schmidhuber,“
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
,” Neural Networks, Vol. 18, No. 5-6, pp. 602-610, March 2005
In this paper, we present bidirectional Long Short Term Memory (LSTM) networks, and a modified, full gradient version of the LSTM learning algorithm. We evaluate Bidirectional LSTM (BLSTM) and several other network architectures on the benchmark task of framewise phoneme classification, using the TIMIT database. Our main findings are that bidirectional networks outperform unidirectional ones, and Long Short Term Memory (LSTM) is much faster and also more accurate than both standard Recurrent Neural Nets (RNNs) and time-windowed Multilayer Perceptrons (MLPs). Our results support the view that contextual information is crucial to speech processing, and suggest that BLSTM is an effective architecture with which to exploit it. 1 1 An abbreviated version of some portions of this article appeared in ( Graves and Schmidhuber, 2005), as part of the IJCNN 2005 conference proceedings, published under the IEEE copyright.
C.Jin, W.H.Li, C.Ji, X.Z.Jin, Y.B.Guo, “
Bi-Directional Long Short-Term Memory Neural Networks for Chinese Word Segmentation
,” Journal of Chinese Information Processing, Vol. 32, No. 2, pp. 29-37, February 2018
Chinese word segmentation(CWS)is a fundamental issue of Chinese language processing(NLP).which affects the subsequent NLP tasks substantially.At present,the state-of-the-art solution is based on the classical machine learning model.Recently,Long Short-term Memory(LSTM)model has been proposed to solve the long-term dependencies in classical RNN model,and already well daapted in various kinds of NLP tasks.As for CWS task,we add a layer of backward LSTM based on unidirectional classical LSTM to build a Bi-directional Long Short-term Memory Neural Network model(Bi-LSTM).And we also propose a contribution rate to balance the matrix's value in forward LSTM layer and backward LSTM layer.We design four experiments to demonstrate that our model is reliable and preferable.
Y.Bengio, P.Simard, P.Frasconi, “
Learning Long-Term Dependencies with Gradient Descent is Difficult
,” IEEE Transactions on Neural Networks, Vol. 5, No. 2, pp. 157-166, February 2002
Abstract Recurrent neural networks can be used to map input sequences to output sequences, such as for recognition, production or prediction problems. However, practical difficulties have been reported in training recurrent neural networks to perform tasks in which the temporal contingencies present in the input/output sequences span long intervals. We show why gradient based learning algorithms face an increasingly difficult problem as the duration of the dependencies to be captured increases. These results expose a trade-off between efficient learning by gradient descent and latching on information for long periods. Based on an understanding of this problem, alternatives to standard gradient descent are considered.
R.Pascanu, T.Mikolov, Y.Bengio, “
On the Difficulty if Training Recurrent Neural Networks
,” in Proceedings of the 30th International Conference on Machine Learning, pp. 1301-1310,Atlanta, Georgia, USA, June 2013
Abstract: There are two widely known issues with properly training Recurrent Neural Networks, the vanishing and the exploding gradient problems detailed in Bengio et al. (1994). In this paper we attempt to improve the understanding of the underlying issues by exploring these problems from an analytical, a geometric and a dynamical systems perspective. Our analysis is used to justify a simple yet effective solution. We propose a gradient norm clipping strategy to deal with exploding gradients and a soft constraint for the vanishing gradients problem. We validate empirically our hypothesis and proposed solutions in the experimental section.
S.Hochreiter and J.Schmidhuber,“
Long Short-Term Memory
,” Neural Computation, Vol. 9, No. 8, pp. 1735-1780, November 1997
Currently,the dominant state-of-the-art methods for Chinese word segmentation are based on character tagging methods by using traditional machine learning technology. However,there are some disadvantages in the traditional machine learning methods: artificially configuring and extracting features from Chinese texts,high dimension of the dictionary,long training time by just exploiting CPUs. This paper proposed an improved method based on long short-term memory( LSTM) network model. It used different tag set and added pre-trained character embeddings to perform Chinese word segmentation. Compared with the best result in Bakeoff and state-of-the-art methods,this paper conducted the experiments on common used corpuses. The results demonstrate that traditional machine learning methods are exceeded by the methods based on LSTM network. By using six-tag-set and adding pre-trained character embedding,the proposed method can reach the relatively highest performance on Chinese word segmentation. Then,it can greatly reduce the training time of deep neural network model by using GPUs. Moreover,the methods based on LSTM network can easily applied to other sequence labeling tasks in natural language processing( NLP).
Y.S.Yao and Z.Huang, “
Bi-directional LSTM Recurrent Neural Network for Chinese Word Segmentation
,” in Proceedings of the 23rd International Conference on Neural Information Processing, pp. 345-353,Kyoto, Japan, October 2016
Recurrent neural network (RNN) has been broadly applied to natural language process (NLP) problems. This kind of neural network is designed for modeling sequential data and has been testified to be...
T.Mikolov, K.Chen, G.Corrado, J.Dean, “
Efficient Estimation of Word Representations in Vector Space,”
Abstract: We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
H.Tseng, P.Chang, G. AndrewG, D.Jurafsky, C.Manning, “
A Conditional Random Field Word Segmenter for Sighan Bakeoff 2005
>, ”in Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing, pp. 168-171,Jeju, Korea, October 2005
... With the development of the Bakeoff (an international competition of NLP), many researchers have been widely involved. It has caused Chinese word segmentation technology to become the focus of research and has made great progress[1]. At present, the main methods include methods based on dictionary, methods based on statistical model, and methods based on deep neural network. ...
Review of Chinese Automatic Word Segmentation
1
2011
... The method based on dictionary, also known as methods based on string matching or methods based on mechanical segmentation, is an earlier method for segmentation. It mainly compares the input sentences with the manually constructed dictionaries, identifies the words contained in the dictionary, and then achieves the segmentation of sentences. According to the scanning method, it includes bidirectional scanning, forward matching, and inverse matching [2]. The advantages of the method are strong pertinence, and the accuracy of segmentation is high facing words contained in dictionaries. However, the shortcomings are transparent. This method cannot deal with the problem of unknown words and word ambiguity effectively. It also has poor adaptability to different fields, and the cost of manual maintenance of dictionaries is high. ...
Chinese Word Segmentation as Character Tagging
1
2003
... This method based on statistical model usually takes Chinese word segmentation as a sequence tagging problem. It solves the problem of identifying unknown words and has gradually become the mainstream method. Xue[3] et al. first proposed tagging the corpus into the four tag set of (B, M, E, S) and realized the segmentation task based on the maximum entropy(ME) model. Liu [4]realized Chinese lexical analysis based on the hidden Markov model(HMM) model. Qianand others [5] researched the techniques of word segmentation in ancient and modern Chinese, and they realized the segmentation of Chu Ci based on the HMM model. Collobert[6] implemented segmentation tasks with subclassification conditional random field(CRF).Zhao[7] provided more tag selection based on the CRF model to improve the segmentation effect. However, these methods based on statistical model require a large number of statistical features. The performance of word segmentation network relies seriously on the quality of the artificial design features. With an increase in the number of features, the training is easy to overfit, the generalization ability of modelis poor, and the training time is increasing. ...
Chinese Lexical Analysis Using Cascaded Hidden Markov Model
1
2004
... This method based on statistical model usually takes Chinese word segmentation as a sequence tagging problem. It solves the problem of identifying unknown words and has gradually become the mainstream method. Xue[3] et al. first proposed tagging the corpus into the four tag set of (B, M, E, S) and realized the segmentation task based on the maximum entropy(ME) model. Liu [4]realized Chinese lexical analysis based on the hidden Markov model(HMM) model. Qianand others [5] researched the techniques of word segmentation in ancient and modern Chinese, and they realized the segmentation of Chu Ci based on the HMM model. Collobert[6] implemented segmentation tasks with subclassification conditional random field(CRF).Zhao[7] provided more tag selection based on the CRF model to improve the segmentation effect. However, these methods based on statistical model require a large number of statistical features. The performance of word segmentation network relies seriously on the quality of the artificial design features. With an increase in the number of features, the training is easy to overfit, the generalization ability of modelis poor, and the training time is increasing. ...
Research on Automatic Word Segmentation and POS Tagging For Chu Ci b Based on HMM
1
2014
... This method based on statistical model usually takes Chinese word segmentation as a sequence tagging problem. It solves the problem of identifying unknown words and has gradually become the mainstream method. Xue[3] et al. first proposed tagging the corpus into the four tag set of (B, M, E, S) and realized the segmentation task based on the maximum entropy(ME) model. Liu [4]realized Chinese lexical analysis based on the hidden Markov model(HMM) model. Qianand others [5] researched the techniques of word segmentation in ancient and modern Chinese, and they realized the segmentation of Chu Ci based on the HMM model. Collobert[6] implemented segmentation tasks with subclassification conditional random field(CRF).Zhao[7] provided more tag selection based on the CRF model to improve the segmentation effect. However, these methods based on statistical model require a large number of statistical features. The performance of word segmentation network relies seriously on the quality of the artificial design features. With an increase in the number of features, the training is easy to overfit, the generalization ability of modelis poor, and the training time is increasing. ...
A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning
4
2008
... This method based on statistical model usually takes Chinese word segmentation as a sequence tagging problem. It solves the problem of identifying unknown words and has gradually become the mainstream method. Xue[3] et al. first proposed tagging the corpus into the four tag set of (B, M, E, S) and realized the segmentation task based on the maximum entropy(ME) model. Liu [4]realized Chinese lexical analysis based on the hidden Markov model(HMM) model. Qianand others [5] researched the techniques of word segmentation in ancient and modern Chinese, and they realized the segmentation of Chu Ci based on the HMM model. Collobert[6] implemented segmentation tasks with subclassification conditional random field(CRF).Zhao[7] provided more tag selection based on the CRF model to improve the segmentation effect. However, these methods based on statistical model require a large number of statistical features. The performance of word segmentation network relies seriously on the quality of the artificial design features. With an increase in the number of features, the training is easy to overfit, the generalization ability of modelis poor, and the training time is increasing. ...
... At present, the most commonly used method of word vector representation is based on deep neural network. The method based on deep neural network can abstruse the features of the Chinese character by multiple hidden layers network and represent each Chinese character as a low dimensional real number vector. Therefore, this method can not only effectively avoid the problem of data sparsity, but also better represent the semantic relations between Chinese characters. In paper [6], Collobert used a method ofvector representation based on a deep neural network language model to deal with various natural language processing tasks. Mikolov had proposed two representations of vectors inpaper[24].One is the continuous bag-of-words (CBOW) model that uses the words around to predict the current word, and the other, called the continuous skip-gram model, is the opposite because it uses the current word to predict the surrounding words.These two methods can all represent similar words in a vector space with smaller angles. ...
... In order to further verify the performance of the BI-GRU-CRF model, we compare this model with some models proposed by previous scholars.Table 3 shows some comparisons between the model performance in this paper and some research results of other scholars in the word segmentation field. All these methods were the best model of Chinese word segmentation at that time. Tseng[25] represents a Chinese word segmentation model based on CRF.Collobert[6] represents a Chinese word segmentation model based on a deep neural network model. Chen[14] represents a LSTM model of two character embedded vectors, and the model mounts a word segmentation dictionary. Yao[23] represents a BI-LSTM model with three BI-LSTM layers.From the results of Table 3, we can see that our model can achieve similar segmentation results without mounting the word segmentation dictionary and stacking the layers of neural network. It is enough to prove the better performance of the BI-GRU-CRF model. ...
... F 1 Value comparison of BI-GRU-CRF with previous research
Models
PKU
MSRA
CTB6
Tseng[25]
0.950
0.964
—
Collobert [6]
0.946
—
0.894
Chen[14]
0.965
0.974
—
Yao[23]
0.965
0.976
—
BI-GRU-CRF(6tag)
0.966
0.972
0.969
5. Conclusions
In this paper, we propose a BI-GRU-CRF Chinese word segmentation model based on GRU neural network. This model not only inherits the features of the GRU unit that are easy to train, but also can use word information and neighbor tags to segment words. We add the pre-trained characters vectors to carry out word segmentation experiments with the four-tag-set and six-tag-set respectively on PKU, MSRA, and CTB6 corpuses. Then, we compare the model performance with other typical word segmentation models: CRF, GRU, and BI-GRU models, along with some research results of other scholars in the word segmentation field. The experimental results show that the BI-GRU-CRF model has better segmentation performance, and the tagging method of six-tag-set can improve the segmentation performance. Future work includes stacking GRU network layers and mounting word segmentation dictionary to improve segmentation performance, and we will apply this model to specific fields. ...
Effective Tag Set Selection in Chinese Word Segmentation via Conditional Random Field Modeling
1
2006
... This method based on statistical model usually takes Chinese word segmentation as a sequence tagging problem. It solves the problem of identifying unknown words and has gradually become the mainstream method. Xue[3] et al. first proposed tagging the corpus into the four tag set of (B, M, E, S) and realized the segmentation task based on the maximum entropy(ME) model. Liu [4]realized Chinese lexical analysis based on the hidden Markov model(HMM) model. Qianand others [5] researched the techniques of word segmentation in ancient and modern Chinese, and they realized the segmentation of Chu Ci based on the HMM model. Collobert[6] implemented segmentation tasks with subclassification conditional random field(CRF).Zhao[7] provided more tag selection based on the CRF model to improve the segmentation effect. However, these methods based on statistical model require a large number of statistical features. The performance of word segmentation network relies seriously on the quality of the artificial design features. With an increase in the number of features, the training is easy to overfit, the generalization ability of modelis poor, and the training time is increasing. ...
Overview of Speech Recognition based on Deep Learning
1
2017
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
Applications of Deep Convolutional Neural Network in Computer Vision
1
2016
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
A Survey on Deep Learning for Natural Language Processing
1
2016
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
A Neural Probabilistic Language Model
1
2003
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
Deep Learning for Chinese Word Segmentation and POS Tagging
4
2013
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
... Inspired by the paper [12], we abstract Chinese word segmentation task as a character-based sequence tagging task. That is to say, we use the neural network model to predict the tags for each input character. The model will tag every character as one of "BMES" set. On the basis of the Chinese word segmentation model proposed in paper [12], in this paper, the network unit is replaced by the gated recurrent unit(GRU) which can deal with the long distance information, and the CRF layer is added after the output layer to form a bidirectional gated recurrent unit conditional random field (BI-GRU-CRF) model. We predict the whole tag sequence by using the sentence level tag information between the tags. ...
... ], we abstract Chinese word segmentation task as a character-based sequence tagging task. That is to say, we use the neural network model to predict the tags for each input character. The model will tag every character as one of "BMES" set. On the basis of the Chinese word segmentation model proposed in paper [12], in this paper, the network unit is replaced by the gated recurrent unit(GRU) which can deal with the long distance information, and the CRF layer is added after the output layer to form a bidirectional gated recurrent unit conditional random field (BI-GRU-CRF) model. We predict the whole tag sequence by using the sentence level tag information between the tags. ...
... In this paper, based on the basic Chinese word segmentation model proposed in paper [12], the BI-GRU-CRF network is added to the basic model, and the specific training flow chart is shown in Figure 6. ...
Gated Recursive Neural Network for Chinese Word Segmentation
1
2015
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
Long Short-Term Memory Neural Networks for Chinese Word Segmentation
3
2015
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
... In order to further verify the performance of the BI-GRU-CRF model, we compare this model with some models proposed by previous scholars.Table 3 shows some comparisons between the model performance in this paper and some research results of other scholars in the word segmentation field. All these methods were the best model of Chinese word segmentation at that time. Tseng[25] represents a Chinese word segmentation model based on CRF.Collobert[6] represents a Chinese word segmentation model based on a deep neural network model. Chen[14] represents a LSTM model of two character embedded vectors, and the model mounts a word segmentation dictionary. Yao[23] represents a BI-LSTM model with three BI-LSTM layers.From the results of Table 3, we can see that our model can achieve similar segmentation results without mounting the word segmentation dictionary and stacking the layers of neural network. It is enough to prove the better performance of the BI-GRU-CRF model. ...
... F 1 Value comparison of BI-GRU-CRF with previous research
Models
PKU
MSRA
CTB6
Tseng[25]
0.950
0.964
—
Collobert [6]
0.946
—
0.894
Chen[14]
0.965
0.974
—
Yao[23]
0.965
0.976
—
BI-GRU-CRF(6tag)
0.966
0.972
0.969
5. Conclusions
In this paper, we propose a BI-GRU-CRF Chinese word segmentation model based on GRU neural network. This model not only inherits the features of the GRU unit that are easy to train, but also can use word information and neighbor tags to segment words. We add the pre-trained characters vectors to carry out word segmentation experiments with the four-tag-set and six-tag-set respectively on PKU, MSRA, and CTB6 corpuses. Then, we compare the model performance with other typical word segmentation models: CRF, GRU, and BI-GRU models, along with some research results of other scholars in the word segmentation field. The experimental results show that the BI-GRU-CRF model has better segmentation performance, and the tagging method of six-tag-set can improve the segmentation performance. Future work includes stacking GRU network layers and mounting word segmentation dictionary to improve segmentation performance, and we will apply this model to specific fields. ...
Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation
2
2014
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
... Therefore, LSTM[21] and GRU[15] cells have been proposed to replace tanh activation functions in traditional RNN networks in order to solve these problems. They are all the cells based on the gates, in which LSTM has the input gate, the forget gate, and the output gate.GRU is an improved model that is more concise and efficient than LSTM. It only has thereset gate and the update gate, where the update gate combines the input gate and the forget gate in the LSTM. The internal structure ofthe GRU cell is shown in Figure 2. ...
An Empirical Exploration of Recurrent Network Architectures
1
2015
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
2
2005
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
... We need not only the past information of the text sequencebut also the future information of the text sequence when dealing with Chinese word segmentation task. However, the unidirectional RNN network cannot deal with such a problem well. Therefore, the bidirectional RNN network[17] is more suitable for Chinese word segmentation tasks, because it can simultaneously utilize the past and future input features. The structure of the bidirectional GRU network is shown in Figure 3. ...
Bi-Directional Long Short-Term Memory Neural Networks for Chinese Word Segmentation
1
2018
... In recent years, deep neural networks have achieved remarkable results in the fields of speech recognition [8] and image processing [9] by relying on their advantages of automatically extracting deep abstract features from the original data and avoiding complex artificial feature design. At the same time, deep learning has also shown its unique advantagesin the NLP task[10]. Bengio[11] put forward a probabilistic language model based on neural network. Zheng[12] took the lead in applying the neural network into the field of Chinese word segmentation and accelerated the training process by using the perceptron algorithm. Then, Chenused the gated recursive neural network(GRNN) model[13] and the long short-term memory (LSTM) model[14]for Chinese word segmentation in order to solve the problem that general neural networks cannot learn long distance information. The gate unit was used to realize the selection of historical information and solve the problem of long distance information dependency. However, the LSTM structure is relatively complex, and the training time is longer. Cho[15] et al. proposed an improved gated recurrent unit (GRU) model. Jozefowicz[16]verified that the GRU model is much easier to train than the LSTM model in many problems, and GRU can achieve the same level as LSTM. Both the LSTM and GRU model can only deal with the information of the previous text but cannot deal with the later information. Therefore, Graves[17]proposed a bidirectional RNN model to solve the problem of capturing long distance information in two directions at the same time. Jin and others [18] realized the Chinese word segmentation based on bidirectional LSTM(BI-LSTM), and they introduced the contribution rate to adjust the weights. The experiment of the model achieved good results. ...
Learning Long-Term Dependencies with Gradient Descent is Difficult
1
2002
... In theory, the RNN network can use the hidden layer state state (t) to capture all the preceding input information, but the reality is not so perfect. The related research of Bengio[19] and Pascanu[20] shows that the hidden layer nodes are only simple to use tanh functions in the processing of long distance information in the traditional RNN network, which makes the training easy to fall into the problem of gradient disappearance and gradient explosion. ...
On the Difficulty if Training Recurrent Neural Networks
1
2013
... In theory, the RNN network can use the hidden layer state state (t) to capture all the preceding input information, but the reality is not so perfect. The related research of Bengio[19] and Pascanu[20] shows that the hidden layer nodes are only simple to use tanh functions in the processing of long distance information in the traditional RNN network, which makes the training easy to fall into the problem of gradient disappearance and gradient explosion. ...
Long Short-Term Memory
1
1997
... Therefore, LSTM[21] and GRU[15] cells have been proposed to replace tanh activation functions in traditional RNN networks in order to solve these problems. They are all the cells based on the gates, in which LSTM has the input gate, the forget gate, and the output gate.GRU is an improved model that is more concise and efficient than LSTM. It only has thereset gate and the update gate, where the update gate combines the input gate and the forget gate in the LSTM. The internal structure ofthe GRU cell is shown in Figure 2. ...
Sequence Labeling Chinese Word Segmentation Method based on LSTM Networks
1
2017
... According to the training process of the word segmentation model [22], before the text sequence is input to the BI-GRU-CRF model, the text should be transformed into a low dimensional character vector abstracting the features of the word as the input of the network model. All the low dimensional vectors are stored in the dictionary D of the lookup layer. Through this dictionary D, the text sequence can be transformed to the corresponding vector sequence after the lookup layer. It has been shown in paper [23] that word embedding plays a vital role in improving sequence tagging performance. ...
Bi-directional LSTM Recurrent Neural Network for Chinese Word Segmentation
3
2016
... According to the training process of the word segmentation model [22], before the text sequence is input to the BI-GRU-CRF model, the text should be transformed into a low dimensional character vector abstracting the features of the word as the input of the network model. All the low dimensional vectors are stored in the dictionary D of the lookup layer. Through this dictionary D, the text sequence can be transformed to the corresponding vector sequence after the lookup layer. It has been shown in paper [23] that word embedding plays a vital role in improving sequence tagging performance. ...
... In order to further verify the performance of the BI-GRU-CRF model, we compare this model with some models proposed by previous scholars.Table 3 shows some comparisons between the model performance in this paper and some research results of other scholars in the word segmentation field. All these methods were the best model of Chinese word segmentation at that time. Tseng[25] represents a Chinese word segmentation model based on CRF.Collobert[6] represents a Chinese word segmentation model based on a deep neural network model. Chen[14] represents a LSTM model of two character embedded vectors, and the model mounts a word segmentation dictionary. Yao[23] represents a BI-LSTM model with three BI-LSTM layers.From the results of Table 3, we can see that our model can achieve similar segmentation results without mounting the word segmentation dictionary and stacking the layers of neural network. It is enough to prove the better performance of the BI-GRU-CRF model. ...
... F 1 Value comparison of BI-GRU-CRF with previous research
Models
PKU
MSRA
CTB6
Tseng[25]
0.950
0.964
—
Collobert [6]
0.946
—
0.894
Chen[14]
0.965
0.974
—
Yao[23]
0.965
0.976
—
BI-GRU-CRF(6tag)
0.966
0.972
0.969
5. Conclusions
In this paper, we propose a BI-GRU-CRF Chinese word segmentation model based on GRU neural network. This model not only inherits the features of the GRU unit that are easy to train, but also can use word information and neighbor tags to segment words. We add the pre-trained characters vectors to carry out word segmentation experiments with the four-tag-set and six-tag-set respectively on PKU, MSRA, and CTB6 corpuses. Then, we compare the model performance with other typical word segmentation models: CRF, GRU, and BI-GRU models, along with some research results of other scholars in the word segmentation field. The experimental results show that the BI-GRU-CRF model has better segmentation performance, and the tagging method of six-tag-set can improve the segmentation performance. Future work includes stacking GRU network layers and mounting word segmentation dictionary to improve segmentation performance, and we will apply this model to specific fields. ...
Efficient Estimation of Word Representations in Vector Space,”
1
2013
... At present, the most commonly used method of word vector representation is based on deep neural network. The method based on deep neural network can abstruse the features of the Chinese character by multiple hidden layers network and represent each Chinese character as a low dimensional real number vector. Therefore, this method can not only effectively avoid the problem of data sparsity, but also better represent the semantic relations between Chinese characters. In paper [6], Collobert used a method ofvector representation based on a deep neural network language model to deal with various natural language processing tasks. Mikolov had proposed two representations of vectors inpaper[24].One is the continuous bag-of-words (CBOW) model that uses the words around to predict the current word, and the other, called the continuous skip-gram model, is the opposite because it uses the current word to predict the surrounding words.These two methods can all represent similar words in a vector space with smaller angles. ...
A Conditional Random Field Word Segmenter for Sighan Bakeoff 2005
2
2005
... In order to further verify the performance of the BI-GRU-CRF model, we compare this model with some models proposed by previous scholars.Table 3 shows some comparisons between the model performance in this paper and some research results of other scholars in the word segmentation field. All these methods were the best model of Chinese word segmentation at that time. Tseng[25] represents a Chinese word segmentation model based on CRF.Collobert[6] represents a Chinese word segmentation model based on a deep neural network model. Chen[14] represents a LSTM model of two character embedded vectors, and the model mounts a word segmentation dictionary. Yao[23] represents a BI-LSTM model with three BI-LSTM layers.From the results of Table 3, we can see that our model can achieve similar segmentation results without mounting the word segmentation dictionary and stacking the layers of neural network. It is enough to prove the better performance of the BI-GRU-CRF model. ...
... F 1 Value comparison of BI-GRU-CRF with previous research
Models
PKU
MSRA
CTB6
Tseng[25]
0.950
0.964
—
Collobert [6]
0.946
—
0.894
Chen[14]
0.965
0.974
—
Yao[23]
0.965
0.976
—
BI-GRU-CRF(6tag)
0.966
0.972
0.969
5. Conclusions
In this paper, we propose a BI-GRU-CRF Chinese word segmentation model based on GRU neural network. This model not only inherits the features of the GRU unit that are easy to train, but also can use word information and neighbor tags to segment words. We add the pre-trained characters vectors to carry out word segmentation experiments with the four-tag-set and six-tag-set respectively on PKU, MSRA, and CTB6 corpuses. Then, we compare the model performance with other typical word segmentation models: CRF, GRU, and BI-GRU models, along with some research results of other scholars in the word segmentation field. The experimental results show that the BI-GRU-CRF model has better segmentation performance, and the tagging method of six-tag-set can improve the segmentation performance. Future work includes stacking GRU network layers and mounting word segmentation dictionary to improve segmentation performance, and we will apply this model to specific fields. ...








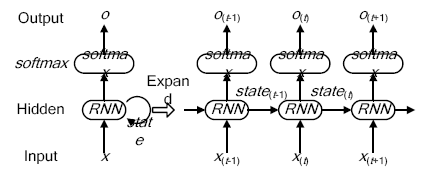
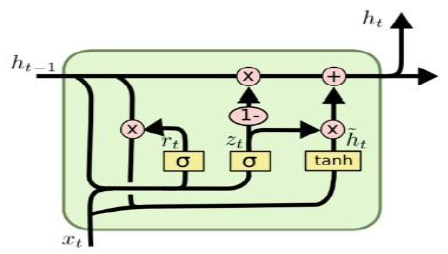
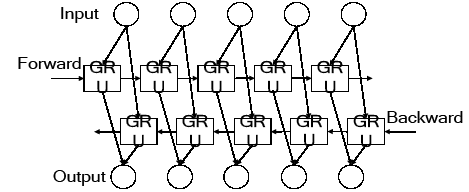
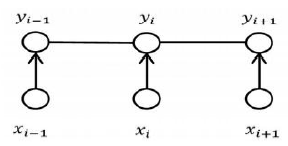
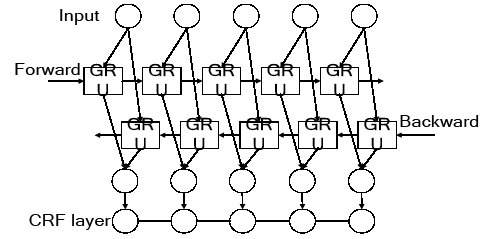
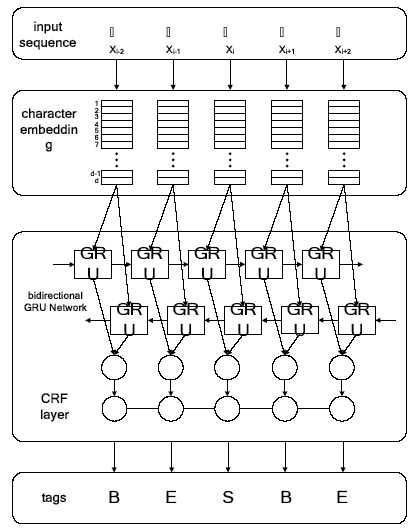



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}