







1. Introduction
Cloud computing and big data are two major research hotspots in the current industrial and academic information revolution. As the cost of cloud data storage continues to decrease, more and more people accept and are willing to use cloud data anytime, anywhere. The large-scale, high-speed, and diverse characteristics of big data [1] make it different from “traditional data”. However, the content of traditional privacy protection theories and technologies like encryption schemes and access control of small data servers for single-type data can’t cover big data privacy issues anymore. The conflict between privacy and new technological changes runs throughout the history of information technology [2].
With the expansion of data scale, data owners have more and more complex data privacy requirements, and data managers have higher and higher requirements for data users’ usage rights management. Data access constraints have also increased, and data access models have been more complex. The contradiction between security and efficiency, security and effectiveness of access is becoming more prominent. New research, such as homomorphic encryption, differential privacy protection, etc., have certain applications in data analysis, data mining, etc. Fuzzification was originally designed to protect personal privacy in data distribution. However, the stronger the computing power based on the connection, the weaker the protection ability of the fuzzification. The preprocessing of global reasoning has also made the efficiency of practical applications a bottleneck and cannot meet the needs of user privacy protection. When all the data is publicized, it will cause privacy leakage and all hidden will cause the information value of the data to be unable to be reflected. How to use the data efficiently without leaking privacy has become a problem that everyone is paying more and more attention to.
This paper studies the use of privacy protection for individual users of specific data, and strives to use the data to resist the inference attack effectively and timely to protect the unauthorized/unauthorized data of individuals/others. The main contents of this article include:
1) XML document privacy preserving model and application of dynamic context. We focus on how to distinguish user query permissions through different levels of context to effectively resist real-time reasoning attacks. Most importantly is how to organize the prior knowledge domain based on user ontology into a dynamic knowledge context, provide a decision algorithm that examines to privacy leakage caused by reasoning in the operation process, and realize the prevention of privacy leakage caused by dynamic context continuous query.
2) Representation of privacy. The access control ACL’s representation of private data is usually static. We have to solve how to achieve incompatible matching and verification through dynamic description.
3) XML document semantic encoding. “AND” operation is the fastest operation of the computer; we have to take advantage of this to realize the real-time operation response through semantic encoding storage representation scheme.
The full text is structured as follows: Chapter 2 introduces related research content, results, and shortcomings. Chapter 3 introduces the dynamic context-based privacy protection model. Chapter 4 give the key technology at the application level based on privacy bipartite graph and XML document semantic encoding. The XML privacy protection scheme against the inference attack is given, and the corresponding case analysis and experimental result analysis are given in Chapter 5. Finally, the summary and prospect are given.
2. Background
2.1. Context
Dey and Abow [3] define context as any information used to characterize an entity’s situation, such as the entity's attributes, date, location, etc. The entity may be a person, a place, a user, an application, or a related object of interaction between user and application. Paper [4] applies context information to the entire access control process, based on context control access to the actual feasibility of the service, and proposes context-sensitive verification methods, and security levels for different levels of entities to check the authenticity of the claims. Zhang [5] defines the context as the relationship of data in-lining, and gives the context constraints required for access control in the decision process from a logical perspective. The condition is encapsulated into specific variables, constants, and a first-order predicate expression of a logical operator. The formula is given a specific value in the dynamic access control.
SS Emami and S. Zokaei [6] gave the access control model of PCEs (Pervasive Computing Environments), and proposed long-term context and short-term context concepts for different levels of users, completes access control respectively by domain management DA (Diamond Admin) and session management SA (Session Admin). PCEs dynamically assign roles based on changes to context predicates, activating user permissions through “Context Prerequisites”.
The paper [7] summarizes the network privacy protection technology and proposes that Web privacy protection technology based on semantic is one of the hotspots of current research. Considering the Semantic Web environment, a large number of individuals between two physical Web services and Web Agents privacy information interaction, privacy protection of the Semantic Web environment will face greater challenges [8-9].
However, most of the existing contexts are still represented by static attributes, which are lacking semantic associations.
2.2. Reasoning Attack
According to the process state of reasoning, the reasoning attack is based on static data mining; one is based on dynamic knowledge accumulation. According to the reasoning technology, the reasoning attack is based on grammar and the other is based on semantics.
2.2.1. Static Inference Closure
Privacy leakage resulting from reasoning is a major problem in security access control. Most of the methods to solve inference attacks are theoretically obtained through connection queries to obtain a complete security view [10], and detection in the design phase, which is theoretical analysis and idealized prevention of privacy leak. The research [11] discusses security and reasoning validation, simulates the XML database attacks under the function dependencies, and gives security metrics for K-Secrecy validation. The research [12] proposes a method of dynamically combining channel instances based on the idea of inference channel at the design level, and implements dynamic inference rules for function dependence. Without considering the case of “actual implication”, only the constraint rules are used as the basis for inference detection. The research[13] uses the method of reasoning in propositional calculus theory to detect the detection method of data layer privacy leakage, which has certain theoretical guiding significance, but lacks guidance for the implementation of specific data applications.
The existing research on partial formalization theory lacks the execution ability of the actual operation level. In the actual operation, if the result of the user query twice is a coherent topic, then the query result will be connected, or the user connects the query result with the existing release data, which is easy to cause the individual to be identified as a privacy leak. The effective detection methods and prevention techniques in real time are not yet mature.
2.2.2. Grammatical Inference Attack
A common dynamic grammar reasoning attack is to connect Joins of attribute fields of different query results, and can infer the records after Join. The obvious shortcoming is that the storage query results are large in scale and the connection operations of historical queries and new queries are complicated. The Join operation based on Cartesian product is much in the discussion of relational database, but it is rarely based on tree structure [14]. The reasoning based on tree structure is limited to the two operations of “merging” and “expanding”, and then discussion of access control and privacy protections are few.
Because traditional inference attacks are based on grammatical structural connections, the solution [15] is also based on grammar. Preventing inference attacks by XML data grammars usually store the information to be queried as path results, and the information path of the new query is compared with the original path. If the function dependencies on the set overflow, it is judged that there is a privacy leak.
The secure access view obtained at this time can effectively prevent sensitive data from being acquired by the user, but there are some problems in the actual application:
1) The issue of flexibility. Any changes to the XML database cannot be directly applied to the visual VIEW, and the view needs to be updated synchronously. In other words, the reasoning check operation is one-time. At the same time, the source data is separate from the security view, and the engine needs to have enough response space to store the inference extension closure and the security VIEW.
2) The issue of usability. The security view can prevent sensitive data from being accessed again through pruning. Sensitivity is only a necessary condition for connection reasoning. If the sufficient condition does not mean privacy leakage, direct pruning will result in data being unavailable, which will affect the data. The value is reduced.
3) The issue of efficiency. In the face of the top-level structure design of the XML document, the computational complexity of the logical complete inference is very large, and the authorization is divided into node access authorization (structure), and element access authorization (data). In the process of distinguishing, it is impossible to solve the complete closure (the second-order logic of the hierarchy depends on incompleteness), and the security access control cannot be ensured without distinction (path access is the premise of data acquisition).
Although there are improvements to optimize the XML document access control process without reasoning leakage [15], the problem contradiction still focuses on the engine in the actual operation is responsible for query response, matching view, security policy authorization check, forward authorization decision, reverse reasoning Leak check, and a series of operations, the efficiency is not high.
2.2.3. Semantic Reasoning Attack
It is difficult to reflect whether the intrinsic link contains a privacy leak in the privacy decision of the original data depending on the structure. In addition to grammatic-based structural connections to form inference attacks, attacks can be distinguished as semantic-based.
Example 1 We define the attribute of heavy weapons as privacy.
Q: ”Does the cargo ship carry heavy weapons?”----Invalid query
But:
QA: “Which dock does the cargo ship dock?” ----Valid query
QB: “Does the dock have the ability to unload heavy weapons?” ----Valid query
The result of multiple queries has an answer that can be derived from Q.
The disclosure of private information leading by either way of reasoning attack, definitely be which the user can obtain information other than the secure access control through the known information, and finally obtains the information result that was originally inaccessible.
That is to say, the reasoning attack is often carried out within the scope of the existing knowledge domain. Therefore, even if the published data has a reasoning privacy leak, it is also at the system speculative computing level. Facing the user’s query, the real leakage of privacy is the accumulation of knowledge of the user’s query results.
However, there are currently no mature programs for resisting semantic reasoning attacks.
2.3. Motivation
Traditional security services lack semantic extraction and dependence on privacy protection, are not sensitive to context, and are not suitable for dynamically changing network environment conditions.
On the other hand, the research of preventing reasoning attack stays at the prevention level of theoretical analysis and structural improvement of inference closure solution. Ignoring the dynamic attribute changes of users in procedural attacks, the problem of preventing legitimate users from continuously querying for inference attacks during operation cannot be solved comprehensively. In addition, the corresponding access control and privacy protection models are not involved. Moreover, complex inference systems are too rigid and inflexible for privacy protection, and excessive protection in the processing of sensitive data leads to a reduction in data availability.
In order to protect data privacy while accessing data reasonably and efficiently, the transformed environment attributes and dynamic user status should play a necessary role in the access control process. The operation of different scenarios, different users and different stages has an impact on the result of privacy leakage.
3. Privacy Preserving Model based on Dynamic Context
3.1. Issues About Dynamic Data Privacy Protection
3.1.1. Dynamic Data Service Model
The data service model for individual users in the network environment is shown in Figure 1.
Figure 1
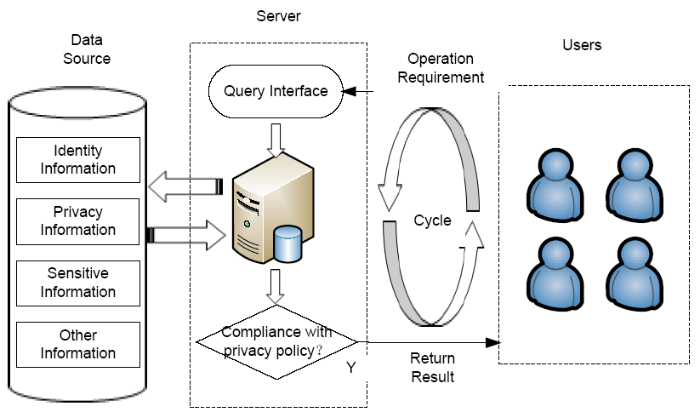
Figure 1.
Data service model framework for individual users
The service provider for data management will return appropriate service results based on the request from the user terminal in conjunction with the confidentiality criteria of the source data. In this activity, issues related to data privacy include:
When users initiate an operation request, different users have different privileges. The same user obtains different privileges in different environments as well as may acquire different privileges in different environments at different time.
The user’s acquisition of the value of the data is continuously accumulated. The same data information object has different meanings for different users. The data that is private to a user may be sensitive or public to other users. The division of data object is not only different from person to person, but also varies from time to time.
The engine’s data server obtains the user’s operation request through the query interface, and needs to complete the data acquisition, the access authority determination, and whether the final result will not disclose the private information and allow feedback to the user for a series of operations. The organizational structure of the data has great impact on the efficiency of the engine. The engine needs to have efficient data positioning and extraction capabilities. The user can extract the content of the view, which is often a small part of the data associated with the ontology rather than the entire data. The poorly designed organizational structure may cause the engine to crash during the conditional decision process.
User interaction with the engine is cyclical; feedback of one result is not sufficient for privacy protection needs. For an individual user’s interactive multiple query results, whether the connection will form an inference attack or merge with the user’s known information to form a background knowledge attack leads to privacy leakage, the engine needs the ability to have dynamic judgment.
3.1.2. Continuous Query Reasoning Attack
The data itself is pure. When data is linked to an individual, the information it reflects has value, and the nature of the data changes. If there is no special definition, the data that we think is private and unwilling to be disclosed is private data. Most of the attribute data related to the subject is the user’s private data. Most of the data related to the interaction behavior of the subject loses the value of the data if all are hidden, and all the disclosures may cause the subject to be identified. The careful and effective treatment of such data is the focus of this paper, resisting the dynamic leakage caused by the dynamic accumulation of knowledge to stimulate semantic reasoning.
Figure 2
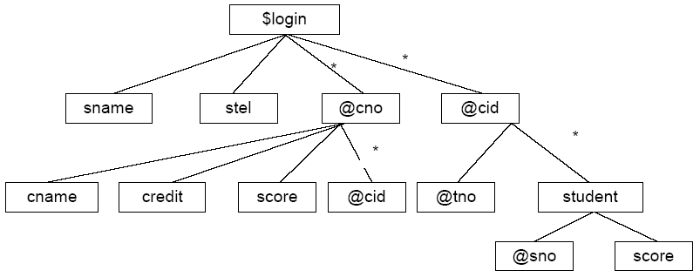
Figure 2.
Visual Tv based on student ontology semantic association
Assume that the currently logged in user (S03) queries within its visible range:
Q1: DB score of student number S04
Q2: Bob’s DB score
Q3: The highest score of the class in the selected course DB
Q4: The student number of the max (score) in the class of the selected course DB
It is known from Tv and R that the score of a non-logged-in user is a sensitive data.
Q1 should obviously be rejected access by the system
For query Q2, the user submits that the query condition is “@cid == ‘DB1’ && sname == ‘Bob’”. The visual VIEW does not have the privilege to get the name of the non-login user, so the username data is not within the scope of the query, although the score of ‘Bob’ is in the queryable range. Assuming that the user has prior knowledge, he knows that Bob’s student number is ‘S04’, so when he wants to submit the DB score of ‘S04’, it is equivalent to Q1 and should be rejected by the system. In any case, according to R, score must be sensitive to the relevant attributes of non-login users.
{Q3, Q4} is a set of queries that do not violate the privacy protection policy, respectively returning a score value and a @sno value. However, {@sno, score} violates the constraint of R, so that the knowledge accumulation of dynamic continuous query will enable users to conduct inference attacks in existing knowledge domains, resulting in leakage of sensitive data privacy. Therefore, the decision processing of Q3 and Q4 is the operation that best reflects the dynamic context advantage of this paper. When the system queries Q3 to obtain the highest score of the current class of the course, the user can feedback to the user under the constraint of R, depending on whether the user knows whose score is the highest. Again, query Q4 depends on whether the user knows what the highest score is. If the current logged-in user thinks that the student number ‘S04’ is the best student in the ‘DB1’ class, then the Q3 query result may lead to the privacy leakage of ‘S04’ and should be rejected by the system.
3.2. Issues About Dynamic Data Privacy Protection
3.2.1. Continuous Query Reasoning Attack
Query is the most common operation of data application. In addition to the influence of access control rules and environment context on permissions, background knowledge is also an important factor. Each query of the user is the accumulation of knowledge and experience; multiple queries will also form a connection attack/reasoning attack, thereby exposing privacy.
In order to realize the XML data privacy preserving of dynamic context resistance reasoning attack, this paper defines the dynamic context and proposes the XML privacy protection model DCPPM (Dynamic Context Privacy Protection Model), as shown in Figure 3.
Figure 3
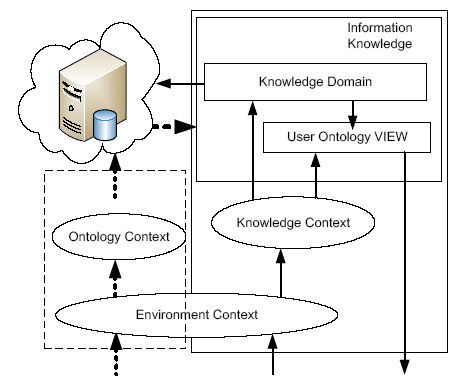
Figure 3.
XML privacy preserving model DCPPM based on dynamic context
DCPPM is divided into two modules: login and query.
The login module is used for the user to obtain the visible range and store the data information that the user can view within the valid login authority. For the currently logged in user, although the cloud has a large amount of data, its visible range is often a limited part related to the subject. If we don’t filter out a large amount of unavailable information and directly query the source information according to the access control rules, the efficiency may be seriously unsatisfactory.
The query module is used for the user to obtain the required information, and stores the query result information that the user can obtain within the valid query range. The user cares about the results of the quantitative query rather than all the information in the visible range, and the data structure does not have to be visible to the user. What the user grasps is also the result of the query. Generally, the data that causes the inference privacy leak is also the data that the user has mastered, not necessarily all the visible data.
3.2.2. Dynamic Context
In this paper, the user’s existing knowledge domain is managed as a dynamic knowledge context in real time. The effective query results are continuously incorporated into the query module of the model as a priori knowledge accumulation. The user doesn’t knows all the privacy even though the user can query the scope. Under the limited permission of the individual user, the visual scope of the reasoning leakage is not necessarily known by the attacker. The knowledge connection attack by the attacker is based on the known knowledge domain (query result). So, this determinant is dynamically changing.
Definition 1 (Knowledge Domain, KD) KD = {(path, value)}, where path represents the document tree path and value represents node value information corresponding to node(path).
Definition 2 (Knowledge Context, KC) KC = {(path). flag}, where path represents the document tree path and flag represents the current path state, 0 is unknown and 1 is a priori known.
Therefore, this article intends to express the dynamic knowledge context as a tree. The leaves represent the data information that the user has mastered. This is the accumulation of user prior knowledge and one of the decision conditions for the next query authorization. The more branches the tree has, the more likely it is to cause data structure associations and leakage of sensitive information.
4. Implementation of Dynamic Context Privacy Preserving
4.1. Function Qr
Definition 3 (Query result, Qr) Given a visual VIEW, Qr is a query, as shown in Function (1).
Specific symbol definitions and information are shown in Table 1.
Table 1. Symbol meaning of function Qr
| Symbol | Meaning |
|---|---|
| Tv | Visual global VIEW tree |
| q | Query condition |
| qr | Query result (not yet feedback to the user) |
Example 3 For query in Example 2:
Q3: Tv(@sno = ’S03’)×{@cid = ’DB1’}×max(score)→88
Q4: Tv(@sno = ’S03’)×{@cid = ’DB1’}×@sno(max(score))→S04
When the ‘88’ and ‘S04’ knowledge information are simultaneously acquired, there is a case where the ‘S04’ privacy is leaked.
4.2. Condition Sensitive and Privacy Bipartite Graph
4.2.1. Condition Sensitive Data
It is generally believed that the process of inference checking of the dynamic context is to determine whether the inference condition is generated to obtain the privacy result that was not released to the user originally, after the current query result qr be included in the dynamic knowledge context set. However, during the initialization phase, the system cannot judge whether the user really does not know who and what the highest score is. How to accurately and timely use KC to judge and determine the user’s prior knowledge is very important. This article is implemented through a privacy bipartite graph of sensitive data.
Definition 4 (Condition Sensitive Data, CSD) CSD={(vi, ci)|Data vi is sensitive under condition ci }.
By definition, we believe that sensitive data is defined by other conditions. The same data have different levels of sensitivity to different users. For example, the score in the subtree ‘student[@sno != $login]’. The same date have different levels of sensitivity to the same user in different conditions. For example, the score in the subtree ‘student[@sno != $login && @sno[max(score)]]’.
Example 4 In Example 1, “Does the cargo ship carry heavy weapons?” is a sensitive query, so, when querying “Which dock does the cargo ship dock?” semantically related to “the dock with unloading heavy weapons qualifications”, the attribute is sensitive. It can be expressed as:
{(v1, c1)|v1: The dock where the cargo ship is docked, c1: Cargo ship docked at Mi Pier with unloading heavy weapons qualification}
4.2.2. Privacy Bipartite Graph
Definition 5 (Privacy Bipartite Graph, PBG) Given G = {({Xi}, {Yi})}, Xi∩Yi = Ø, {xi1, xi2, …, xim}
The PBG is actually used to define a semantic association list, through the storage of the access path of the condition sensitive data CSD in the semantic dependency, including the privacy attribute to prevent the information that can be derived from the next query. In actual operation, the maintenance of the bipartite graph is also dynamic. As the background knowledge of users continues to accumulate, the bipartite graph will become more and more complicated. The effective response to the calculation of the privacy bipartite graph is also an innovation in this paper.
Example 5 In Example 2, the non-logged-in user’s grade is a sensitive data; it can be expressed as:
{(v1, c1)|v1: $login.@cid.student.score, c1: $login.@cid.student.@sno}
{(v2, c2)|v2: $login.@cid.student.@sno, c2: $login.@cid.student.score}
In this condition of the sensitive definition, in Example 2, Query Q3: @cid == ’DB1’ && max(score) and Q4: @cid == ’DB1’ && @sno(max(score)), a pair of mutually incompatible sensitive data information is formed. We add mutually sensitive paths to the privacy bipartite graph:
G1 = {…, ({$login.@cid.student.@sno}, {$login.@cid.student.score}), …}
Expressed in the user’s view range, as shown in Figure 4. We use the path that the user has queried to describe the background knowledge already contained in the KC. Because the two paths are in the X and Y sets of the privacy bipartite graph, the Q3 path is represented by a thick solid line, and the Q4 path is represented by a dashed line. When the path taken (query Q3) is the knowledge background known to the current user, the access path (query Q4) will be denied access, or the access result will be rejected.
Figure 4
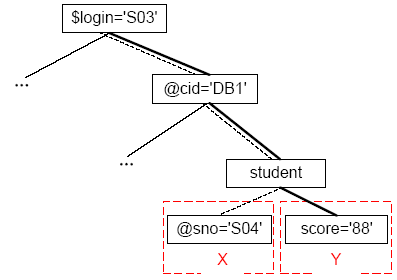
Figure 4.
Continuous query Q3, Q4
4.3. Resistance Reasoning Attack Algorithm KCQ
When the user initiates a query operation, the engine determines whether the result of the inference attack will result in a data access violation of the ACL because of the information in the existing knowledge domain of the user. If there is no privacy leak, the KD is updated, and the result is written to the KC. If there is a privacy leak, the user interface displays a rejection.
In this section, we give a specific implementation algorithm KCQ for inferring detection authorization based on user dynamic context.
| Algorithm 1 KCQ |
|---|
| Input: Tv, q, KD, G |
| Output: qr |
| KCQ (T, q, KC, G) { KC = KD //Initialize user dynamic knowledge context qr = Q(TV, q) //Get the user’s current query result flag = 0 //Real-time judgment of resistance reasoning attacks for XPath in q if G(XPath, KC ) == Y KC = KC∪{XPath} else flag = 1 if flag == 0 KD = KC return qr } |
The KCQ algorithm theoretically gives the idea and steps of resisting inference attacks. In actual operation, other performance issues that must be addressed includes: the acquiring and storage of the dynamic context KC, the judgment of the privacy bipartite graph, the efficiency of a series of decisions affecting the return of qr, etc.
4.4. XML Document Semantic Encoding
The real-time implementation of resistance to inference attacks means that the execution of the algorithm must be completed within the effective response time. This puts high requirements on the efficiency and performance of the storage and representation of the dynamic knowledge context KC, and the matching and calculation of the privacy bipartite graph G. XML document encoding is an important means of XML data storage, location and extraction. The encoding scheme directly affects the execution efficiency of XML data operations. In this section, we combine the fastest advantage of computer “AND” operation and the possibility that most condition sensitive data are semantically associated in the same subtree. We design an effective semantic encoding scheme against inference attacks.
4.4.1. Analysis of Semantic Encoding Scheme
At present, there are many schemes for XML document tree encoding, such as start-end interval encoding [17], prefix Dewey encoding [18], prime encoding [19], concentric circular cutting encoding [20], etc. Most of the research focused on encoding structure design, indexing scheme improvement, space-time cost optimization, and document update feasibility scheme design.
The main reason why the above encoding scheme is not suitable for this scheme is that it has obvious static features and focuses on the structure. In the design and implementation of the scheme of resistive reasoning attacks, we first need to store the condition-sensitive node location, and the storage needs to be encoded. In the encoding process, we should consider the following points:
First of all, when the semantic visual view is generated, it is a hierarchical structure formed by combining semantic dependencies. Therefore, in the formation process of the path distribution of the user visual view and the privacy bipartite graph node, the child node and the sibling node order are regularly ruled.
Secondly, according to the rules of semantic generation, most of the attributes that can form semantic reasoning belongs to a sub-tree within a certain semantic range; it is possible to generate semantic inference to form knowledge reasoning. Then, for the hierarchical path, it is likely that the root path is overlapping.
Thirdly, considering that the computer is the most efficient in performing the AND operation, we hope to convert the contrast operation of the bipartite graph into the encoded AND operation as much as possible to achieve the desired execution response speed.
4.4.2. Semantic Encoding
According to the above analysis and summary, in order to better respond to the engine and respond to the query condition, we design an encoding scheme that efficiently implements the path computation to determine whether there is privacy leakage in the privacy bipartite graph.
4.4.2.1. LT-BT
We first give an encoding scheme for location tree-binary tree transformation for tree structure: LT-BT encoding. This code is mainly used to encode the DTD structure.
Definition 6 (Location Tree - Binary Tree Encoding, LT-BT Encoding) Given DTD D = (E, A, P, R, r), then:
(1) TLT-BT(r) = 0
(2) If ele
$\cdot$ LT-BT(ele.child[0]) = 0X+0 (‘+’ is Adjoining operation)
$\cdot$ LT-BT(ele.child[1]) = 0X+1
$\cdot$ for each ele.child[i] (i = 2, 3, …) //If the node ele has other children LT-BT(ele.child[i]) = LT-BT(ele.child[i-1])+1
(3) All nodes have a limited application step (1) (2) to generate an encoding scheme.
One of the advantages of the LT-BT encoding scheme is that the paths of the associated subtrees can be quickly compared by AND operations. Since most of the paths that may cause inference are in the same subtree, we also want paths with the same semantics to have the same prefix in the encoding scheme. In this way, when judging the privacy bipartite graph, it can be directly compared by the bitwise “and”.
The second advantage of the LT-BT encoding scheme is the simplicity of the DTD structure. The amount of work for DTD encoding is much smaller than for the entire XML document structure. After encoding the DTD and mapping to the XML document, it is only necessary to consider the one-to-many case to increase the sequence identifier.
Example 7 For VIEW Tv D2 in example 1, in the process of generation with the order of multi-value dependency and function dependency, we convert to a binary tree according to the rule of the left child-right brother according to the standard of the N-dimensional position tree. We can get the LT-BT code of D2 as shown in Figure 5.
Figure 5
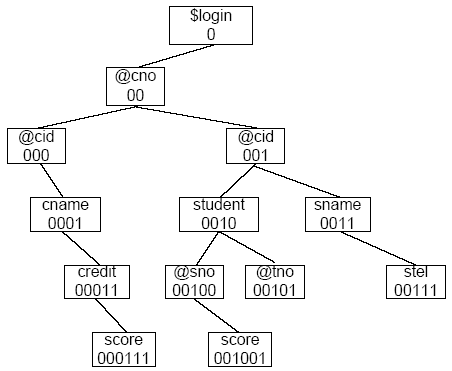
Figure 5.
LT-BT Encoding of D2
Corresponding to the path description in each encoding scheme of D1, we can convert the path of the privacy bipartite graph into 0-1 code form storage. In Example 5, the storage of G1 is:
G1 = {…, ({00100}, {001001}), …}
Thus, in actual operation, the decision process of privacy reasoning is actually the AND operation of the sensitive path encoding in the privacy bipartite graph, which is much more efficient than the conditional judgment of Xpath.
4.4.2.2. TS Encoding
We can further semantically encode the XML document based on LT-BT, which is encoded for the XML document structure.
Definition 7 (Tree Semantic Encoding, TS Encoding) Given DTD D=(E, A, P, R, r) and XML document T╞ D, then:
(1) TS(r) = 1
(2) If ele
$\cdot$ if val(ele) is unique, then TS(val(ele)) = 1X
$\cdot$ if val(ele) is unique, then TS(val(ele)) = 1X.i (i = 0, 1, 10, 11, …)
(3) All nodes have a limited application step (1) (2) to generate an encoding scheme.
TS encoding is a positioning scheme in which LT-BT encoding corresponds to an XML document. The biggest advantage is that it preserves the semantic encoding of the fixed DTD structure. Even if the XML path needs to be refined in the privacy bipartite graph, the original semantic association can be retained.
Example 8 When query Q3 is successful, the existing knowledge domain KD means there will be an update. The accessed paths and results will be merged into the user’s dynamic context KC:
KD= KD∪{(101001.11, ‘88’)}
KC=KC∪{001001}.1
When the query Q4 is executed, the engine compares the AND operation according to the rule ({00100}, {001001}) in the privacy bipartite graph, obtains the judgment result of the violation of the privacy policy, and will reject it.
5. Experiment and Analysis
In this section, we analyze and verifies the privacy protection model proposed in this paper from the aspects of algorithm implementation effectiveness and space-time cost. Firstly, the comparison between the encoding scheme and other encoding schemes in storage space and location response time performance is given. Then, based on the definition of the actual application privacy bipartite graph, the validity verification and time-consuming comparison of real-time resistance reasoning attacks are given. Ranging from information storage, security, timeliness and other aspects, the advantages of the KCQ algorithm are proposed in this chapter.
In order to verify whether the results of the multiple queries are connected to form a response to the privacy leak caused by the inference attack, and verify the real-time response efficiency, our experiment simulates the client and server respectively through two computers (T470, T470P). The experiment adopts Intel (R). Core(TM) i7-7700HQ, 2.8GHz CPU, 8G memory, 64-bit Win 10 operating system, programming using Visual Studio 2010 and DOM parsing XML documents.
In order to compare the execution efficiency, this experiment uses Burr [21] and Ordinary from Proceeding page and xml-actors. In the test set, the maximum tree depth 7 corresponds to a code depth of 7, and the minimum tree depth 4 corresponds to a code depth of 6, for each test document. The specific information is given in Table 2.
Table 2. Information of test data set
| Num | Test set | Storage | Nodes | Max depth | Max depth of coding |
|---|---|---|---|---|---|
| 1 | Proceedings | 56KB | 322 | 7 | 7 |
| 2 | Burr | 16KB | 342 | 4 | 6 |
| 3 | Ordinary | 3KB | 44 | 4 | 6 |
| 4 | XMark-3 | 9.6MB | 41712 | 6 | 6 |
Combined with different access control rules and privacy policies, the four test sets’ preprocessing time of the privacy bipartite graph is shown in Figure 6.
Figure 6
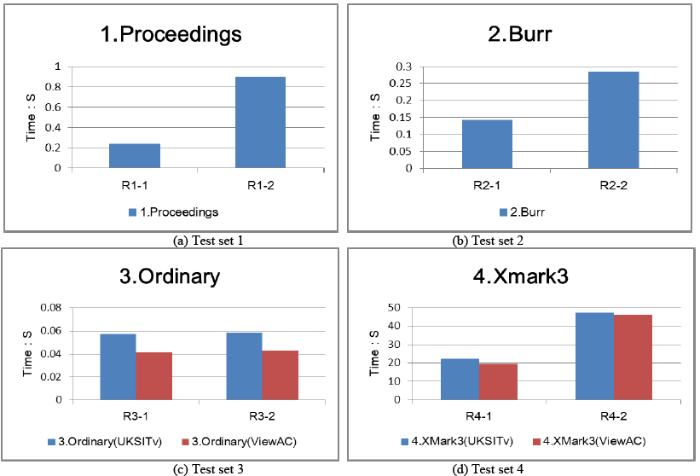
Figure 6.
Encoding preprocessing time for different access control rules
Here, the access control rule uses the UKSITv algorithm [16] for the visual range processing of test set 1 and test set 2, and the view AC scheme [22] and UKSITv [16] algorithm for the visual range processing of test set 3 and test set 4, respectively. The encoded pre-processing response time shown in Figure 6 is calculated after the rule processes the document. It can be seen that the encoding preprocessing process is mainly affected by the size of the access control rule and the access control scheme. The larger the data size, the longer the encoding time. The fewer the view’s redundant structure nodes \, the shorter the encoding time.
As the results of the query continue to accumulate, the storage space of different users’ own contexts is also increasing. Thanks to the LT-BT encoding, the storage of the tree structure path to 0; 1 encoding is not significant for the storage increment of the dynamic knowledge context KC, as shown in Figure 7.
Figure 7
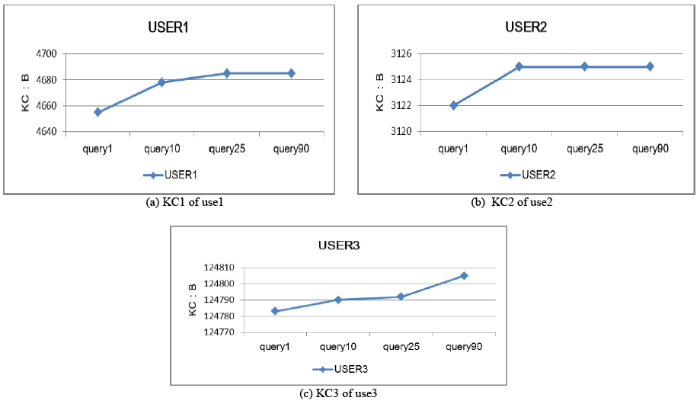
Figure 7.
Storage of different user dynamic context KC under continuous queries
The experiment simulates the user query effect in multiple stages, and defines different queries according to the actual data semantics violating the privacy bipartite graph. The experimental results of the KCQ algorithm are shown in Figure 8.
Figure 8
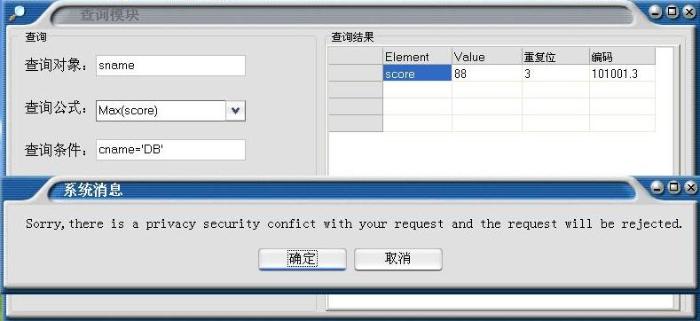
Figure 8.
Real-time inference attack response of algorithm KCQ
6. Conclusion
Combining the semantic nature of big data objects and the influence of network dynamic environment on the authorization of individual user data, this paper studies the privacy protection scheme of XML data based on dynamic context layering, which aims to facilitate users to use data value efficiently and maximally. At the same time, it can meet the needs of original data privacy protection. This paper mainly contributes as follows:
1) We propose and define dynamic contexts. This paper fully considers the background prior knowledge of user dynamic changes, introduces dynamic context as an important basis for privacy protection, and avoids excessive data protection while preventing privacy leakage.
1) We propose a dynamic context-based resisting reasoning attack privacy protection model. Through the dynamic context condition sensitivity and privacy bipartite graph concept, combined with semantic association, information association, knowledge domain accumulation and other situations that may cause privacy leakage, this paper analyzes and studies and proposes a resisting reasoning attack DCPPM model.
2) We propose a real-time resistance reasoning attack based on XML document semantic encoding. In the practical application, this paper implements storage and matching through the innovative XML document semantic encoding scheme, which simplifies the heavy judgment work into the computer’s best and fastest “and” operation, and realizes the inference attack caused by the accumulation of prior knowledge of continuous queries.
The above proposed models and implementations only consider a certain level of security issues, while security issues are stereoscopically interacted in a cloud environment. There are still many problems and many aspects worthy of our continued research. For example, the original privacy policy is still static, that is, the user’s own access rights are defined in advance. With the continuous extension of dynamic network services, privacy policies may be continuously updated with policies and regulations, the will of data providers, and the enhancement of malicious attackers. The focus of the next step will be to further consider the changes in the dynamic privacy policy, and adapt to the dynamics of the network environment with a more adaptive dynamic protection scheme.
Acknowledgements
This research is supported by the pre-study fund of PLA University of Science and Technology.
Reference
Architecting Big Data: Challenges, Studies, and Forecasts
,”
Towards a Better Understanding of Context and Context-Awareness
,”
Context Sensitive Access Control
,” in
XML-based Context-Constraint Access Control Policy Management
,”
A Context-Sensitive Dynamic Role-based Access Control Model for Pervasive Computing Environments
,”
Survey on Technologies of Internet Privacy Preservation
,”
Semantic Web Services
,”
A Semantic based Privacy Framework for Web Services
,” in
Protecting Databases from Inference Attacks
,”
Decidability of the Security Against Inference Attacks Using a Functional Dependency on XML Databases
”
The Inference Control of Functional Dependency based on Inference Channel
,”
Approach to Inference Disclosure Detection in Secure Database
,”
The problem of inference disclosure in secure databases that occurs when a generic user circles security mechanism and obtains sensitive data in the database combining the acquired data and application knowledge of the database. To resolve the problem, an approach to inference disclosure detection at data level was proposed. The approach was expressed in form of formal system and detected inference disclosure with logic-based techniques based on database constraints and data user acquired. It is proved theoretically and showed by testing result that the approach can obtain material implications from the acquired data completely and effectively, and its correctness rate of detection can get up to 81.3% with those material implications.
Inference Control of XML based on Inference Tree
,”
Research on Database Reasoning Control Technology
”
Inverted XML Access Control Model based on Ontology Semantic Dependency
,”
On Supporting Containment Queries in Relational Database Management Systems
,” in
Storing and Query in Ordered XML Using a Relational Database System
,” in
A Prime Number Labeling Scheme for Dynamic Ordered XML Trees
,” in
An XML Encoding Scheme based on Concentric Circular Cutting
,”
Niagara, “NIAGARA Experimental Data
[EB/OL],” (
Airavat: Security and Privacy for MapReduce
,”

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}