







1. Introduction
In recent years, the leakage of personal information on the Internet and the increasing assaults on social infrastructure have become the main threats to cyber security [1]. In general, an attacker who wants to implement an attack on a network user must embed the attack code into the network site or let users download an attack program. The JavaScript language is mainly embedded on web pages and can be executed on the web, which is ubiquitous in Internet web pages and used in almost all websites. In addition, there are many other applications that use JavaScript (e.g., Portable Document Format (PDF) tables, Hypertext Markup Language (HTML) emails, etc.), which plays an important role in these applications. This strong dependence creates an opportunity for malicious attackers to invade the victim’s system. The main function of malicious JavaScript code is to discover vulnerabilities in Internet applications and use Cross Site Scripting (XSS) to attack user systems. Therefore, malicious attackers often insert malicious JavaScript code into web pages to attack users.
Besides malicious attackers, many web developers use obfuscation to process their JavaScript code to prevent unauthorized users from stealing their code. For many companies, these JavaScript codes are valuable assets [2]. Nowadays, there are many online free obfuscators available that can simply convert JavaScript code to equivalent obfuscated code. The popularity of free online obfuscators has made the use of JavaScript code obfuscation widely welcomed.
For JavaScript code obfuscation detection, literature [3] describes the necessity of detecting it and considers that obfuscation is the most salient feature of malicious JavaScript. When a JavaScript code is highly obfuscating, it can be considered suspicious. At the same time, code obfuscation brings the contradiction between hiding malicious code and protecting benign script, which leads to a decrease in the false alarm rate of malicious script detection and an increase in false alarms of benign obfuscation scripts. Therefore, the detection and classification of obfuscated JavaScript are necessary.
This paper proposes a method for detecting JavaScript code obfuscation based on Convolutional Neural Networks (CNNs). We used the character matrix feature method of Bigram to extract features of JavaScript code.A CNN model is applied to the JavaScript code obfuscation detection, overcoming the high requirement of the machine code learning and the low accuracy of the obfuscation feature extraction of JavaScript code.
2. Related Work
JavaScript code obfuscation is a classification problem. Because of the superiority of machine learning and data mining in classification and recognition, many researchers have adopted this method to detect JavaScript code obfuscation. In literature [4], a large number of JavaScript obfuscation scripts are collected. By analyzing the basic principles and inherent nature of JavaScript code obfuscation, an N-gram based JavaScript code feature extraction method is proposed. Finally, the machine learning method KNN is used to extract the extracted features. The eigenvectors are learned, and intelligent identification of JavaScript code obfuscation is completed. In literature [5], the number of string variables in JavaScript scripts and the number of dynamic functions are used as features to detect JavaScript obfuscated scripts. One-class Support Vector Machine (SVM) algorithm is used to identify malicious JavaScript obfuscated scripts.
Literature [3] proposes a lightweight method to quickly filter obfuscated JavaScript. The specific operation is to mark the JavaScript text at the letter level and the information theory method and use the information theory method and the single classification SVM to detect the obfuscation. This new theory has a higher detection accuracy than other existing JavaScript code obfuscation detection models. Literature [6] analyzes the external static behavior and the internal dynamic behavior of obfuscated JavaScript code for the problem of confusing malicious JavaScript code that is hard to detect and difficult to undergo deobfuscation. Static analysis uses normal behavior data for training and Principal Component Analysis (PCA), Single Class SVM, and Nearest Neighbor (K-NN) algorithms to detect obfuscation.
In the current research results, although many researchers have used machine learning methods to identify JavaScript code obfuscation, most of these models are shallow machine learning models. Additionally, the accuracy of detection is not particularly high. Therefore, this paper proposes a JavaScript code obfuscation detection method based on CNNs. This method extracts the obfuscation feature of JavaScript code through Bigram’s character matrix feature extraction method, simplifies the feature extraction process, and uses CNNs to identify and classify JavaScript code obfuscation, which improves the accuracy of JavaScript code obfuscation detection.
3. JavaScript Code Feature Extraction Method
To address the problems in the existing feature extraction methods such as low execution efficiency and complex feature extraction, this paper proposes a character matrix feature extraction method based on Bigram. According to Bigram, Markov transition probability matrix, and information gain, JavaScript code is processed at the character level and related features are extracted. There are two methods in feature extraction based on Bigram character: 1) Key Character Screening Algorithm and 2) Character Feature Matrix Extraction Algorithm.
3.1. Key Character Screening Algorithm
Since JavaScript code is encoded in ASCII, whose values range from 0 to 255, we proposed a
1) Read and traverse JavaScript code obfuscation.
2) Calculate the information gain value for each character. In the process of feature selection, by calculating the entropy of the target, the method is mainly used to evaluate terms. The greater the information entropy, the more information the words contain, and the greater the role played by the subsequent predictions. The value of the information gain (IG) for each character is calculated using Equation (1).
Where C is a classification with two possible values: Normal and Obfuscated script, which are {C1, C2}, corresponding to the probability of each type respectively. Then, the entropy of C is calculated using Equation (2).
$H(C)=-\sum\limits_{i=0}^{2}{{{p}_{i}}{{\log }_{2}}({{p}_{i}})}$
Where ${{p}_{i}}$ denotes the probability of the corresponding C,t denotes the case of the positive sample, and $\bar{t}$ denotes the case of the negative sample.
3) Store the information gain value corresponding to the ASCII code in the corresponding array position, then sort the array from high to low, select the ASCII code with the highest information gain value, and delete the irrelevant ASCII code.
3.2. Key Character Feature Matrix Extraction Algorithm
In JavaScript code obfuscation, some characters do not exist in normal files. Therefore, the Bigram slide window is used to extract the features of the JavaScript code obfuscation. The specific steps are as follows.
1) Read and traverse the JavaScript code.
2) Generate a
3) Let {Xn, n≥0} be a Markov chain with 128 states 0, 1, 2,
4) Perform a binary window slide on the JavaScript code to count the frequency of occurrence of each character and fill in the corresponding feature matrix. E.g., the coordinate 28, 29 represents the number of occurrences of ASCII value 28.
5) Perform a statistic to calculate the frequency of words at each position. Namely, calculate the sum of the values in each row and divide the sum to get the value of the corresponding position.
4. A Method for Detecting JavaScript Code Obfuscation based on Convolutional Neural Networks
The basic idea of our method is: the data collected from JavaScript code obfuscation is preprocessed based on the characteristics of the Bigram character matrix. Then, the dataset is used as the input of the CNN, which realizes the detection of JavaScript code obfuscation by learning JavaScript character features.
4.1. Data Preprocessing
In addition, since the CNN used is a supervised deep learning method, the collected JavaScript code should be tagged. Supervised learning algorithms analyse the training data and generate inference functions that can be used to map new instances. The optimal scenario will allow the algorithm to correctly determine class labels for invisible instances [10]. In the reverse propagation process of CNN, the gradient descent method is used to modify the weights and thresholds of the network and finally achieve the stability of the entire CNN. Therefore, the JavaScript obfuscation code in the sample set in this paper is defined as 1, which is also defined as a positive sample. The JavaScript normal code in the sample set is defined as 0, which is also defined as a negative sample.
4.2. Detection Method Description
Since CNN has a better learning effect on matrix eigenvectors, we decide to use a CNN to detect JavaScript code and determine whether the JavaScript code is obfuscated. The specific training steps for the model of obfuscated JavaScript code are as follows:
(1) Divide the selected JavaScript code obfuscation into a proper proportion of test sets and training sets; select all samples as training samples. Feature extraction is performed on the samples according to the feature extraction method in the previous section.
(2) Establish a CNN model which uses a simplified version of the vgg-16 model [11] to initialize the convolution kernel and the threshold. Then, select the appropriate activation function and set the appropriate learning rate, number of iterations, and objective function.
(3) Normalize the character matrix feature extracted by the JavaScript code, and then input the normalized data into the CNN to obtain the output result.
(4) Compare the output results with the actual tag values of the input samples. The deviation is calculated using the predefined objective function, and the weights and thresholds of each layer of the neural network model are updated in the backward propagation manner. The deviation in each layer is calculated from the previous layer. Finally, update the weights according to the stochastic gradient descent algorithm.
(5) Stop the training and enter Step (6) when the times of training reaches the predefined value or reaches an ideal training result. Return to Step (3) and continue training the model.
(6) Save the model after the CNN training is over, when the network structure parameters in the CNN tend to be stable. Use the JavaScript code obfuscation test set as input, and then evaluate the CNN detection performance based on the results.
5. Experiments and Analysis
To demonstrate the advantages of CNNs for shallow machine learning, our method will be compared with a JavaScript code obfuscation detection method based on SVM.
5.1. Experimental Index
We use the common machine learning standard to evaluate the proposed method and select the precision rate P, recall rate R, and F-measure value F as experimental performance evaluation metrics, which can be calculated using Equation (3).
$P=\frac{TP}{TP+FP}$
$R=\frac{TP}{TP+FN}$
Where TP is the number of correctly classified JavaScript obfuscated codes, FP is the number of JavaScript normal codes predicted as JavaScript obfuscated codes, and FN is the number of JavaScript obfuscated codes predicted as JavaScript normal codes. Their specific meanings are shown in Table 1.
Table 1. Sample index analysis
| Index | TP | TN | FP | FN |
|---|---|---|---|---|
| Sample type | obfuscated | normal | normal | obfuscated |
| Test result type | obfuscated | normal | obfuscated | normal |
5.2. Experimental Dataset
The dataset used in this paper has two main sources: the JavaScript code on jsDeliver and the code crawled on the Alexa Top 500 website.
jsDeliver: This site contains a large number of JavaScript databases from which non-obfuscated JavaScript code can be downloaded directly.
Table 2. Alexa top 5
| Rank | Website | Category | Access user | Extension | Page views | Include advertisement? |
|---|---|---|---|---|---|---|
| 1 | Facebook.com | Social Network | 540000000 | 35.20% | 570000000000 | Yes |
| 2 | Yahoo.com | Web Portals | 490000000 | 31.80% | 70000000000 | Yes |
| 3 | Live.com | Search Engine | 370000000 | 24.10% | 39000000000 | Yes |
| 4 | Wikipedia.org | Encyclopedia | 310000000 | 20% | 7900000000 | No |
| 5 | MSN.com | Web Portals | 280000000 | 18.10% | 11000000000 | Yes |
Since file obfuscation and non-obfuscation in JavaScript code are unknown, datasets must be preprocessed to facilitate subsequent label processing of experimental data. We obtain 2000 non-obfuscated JavaScript code snippets by manual classification and selection. Then, an online JavaScript obfuscator [13-14] is used to obfuscate the JavaScript code snippets to obtain the corresponding dataset, which is composed of 400 obfuscated JavaScript code snippets and 1500 normal code snippets.
The datasets are classified as shown in Table 3.
Table 3. Dataset classification details
| Category | JavaScript obfuscation code | JavaScript normal code |
|---|---|---|
| Training set | 320 | 1200 |
| Testing Set | 80 | 300 |
The collected JavaScript code samples are divided as a ratio of 4:1, i.e. 320 JavaScript obfuscated codes and 1200 normal codes for model training, and the rest of the codes are used for model test. The training set is used to train the CNNs so that the CNNs learn the JavaScript code to obfuscate the hierarchical features. The testing set is used to evaluate the effectiveness of the CNN model for completing the training and detecting whether there is overfitting [15].
5.3. Experimental Environment
We use the Keras platform for implementation, which is a deep learning library implemented in Python language and can generate deep learning models based on TensorFlow, Theano, and CNTK backends. The experimental environment parameters are shown in Table 4.
Table 4. Experimental environment parameters
| Category | Parameter |
|---|---|
| CPU | 1 core |
| Frequency | 3.40GHZ |
| Memory | 1G |
| Operating system | Ubuntu 12.04 |
5.4. Experimental Results and Analysis
Our method will be compared with a SVM-based JavaScript code obfuscation verification method [16], and we have made some minor adjustments on the simplified version of vgg-16, obtaining two CNN models. Each of these three models has its own advantages and disadvantages. It can be seen in Figure 1 that the precision, recall rate, and F-measure value of the two CNN models and SVM model are different when detecting JavaScript code.
Figure 1
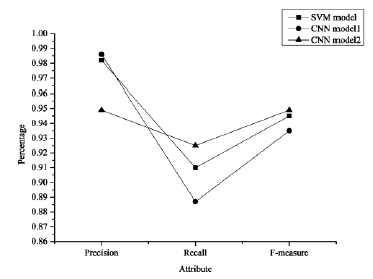
Figure 1.
Comparison between SVM and CNNs Experiments
In Figure 1, the precision, recall, and F-measure values of the SVM method are 98.2%, 91.0%, and 94.5%, respectively. The precision, recall, and F-measure values of the two models of the code obfuscation method based on the CNNs are 98.6%, 88.7%, and 93.5%; 94.9%, 92.5%, and 94.9%. It can be seen from the experimental data that the precision of the CNN model 1 is higher than that of the SVM model, but the recall rate and F-measure value are lower for the CNN model 1. Although the precision of the second model is slightly lower than that of the SVM model, it is slightly higher than that of the SVM in both the recall rate and F-measure value. Based on this, the CNN-based JavaScript code obfuscation detection method we proposed is practical and can improve the model’s requirements for features and enhance the accuracy.
6. Conclusion
We propose a method for detecting JavaScript code obfuscation based on CNNs, which uses the character matrix feature method of Bigram to extract features of JavaScript code and applies a CNN model to the JavaScript code obfuscation detection. Our method overcomes the high requirement of the machine code learning and enhances the low accuracy of the obfuscation feature extraction of JavaScript code. Simulation results show that our method can not only reduce the requirements for the features, but also effectively enhance the accuracy of the detection of JavaScript code obfuscation.
Acknowledgement
This work is supported by the Natural Science Foundation of China (No. 61502118, 61702450) and the Natural Science Foundation of Heilongjiang Province in China(No.F2016028, F2016009, and F2015029).
Reference
Detecting Obfuscated JavaScriptsUsing Machine Learning
,” in
Heap Graph based Software Theft Detection
,”
DOI:10.1109/TIFS.2012.2223685
URL
[Cited within: 1]

As JavaScript is becoming more and more popular, JavaScript programs are valuable assets to many companies. However, the source code of JavaScript programs can be easily obtained and plagiarism of JavaScript programs is a serious threat to the industry. There are techniques like code obfuscation and watermarking which can make the source code of a program difficult to understand by humans and prove the ownership of the program. However, code obfuscation cannot avoid the source code being copied and a watermark can be defaced. In this paper, we use a relatively new technique, software birthmark, to help detect code theft of JavaScript programs. A birthmark is a unique characteristic a program possesses that can be used to identify the program. We extend two recent birthmark systems that extract the birthmark of a software from the run-time heap. We propose a redesigned system with improved robustness and performed extensive experiments to justify the effectiveness and robustness of it. Our evaluation based on 200 large-scale websites showed that our birthmark system exhibits 100% accuracy. We remark that it is solid and ready for practical use.
An Efficient Method for Detecting Obfuscated Suspicious JavaScript based on Text Pattern Analysis
” in
DOI:10.1145/2903185.2903189
URL
[Cited within: 2]
The malicious JavaScript is a common springboard for attackers to launch several types of network attacks, such as Drive-by-Download and malicious PDF delivery attack. In order to elude detection of signature matching, malicious JavaScript is often packed (so-called "obfuscation") with diversified algorithms therefore the occurrence of obfuscation is always a good pointer for potential maliciousness. In this investigation, we propose a light weight approach for quickly filtering obfuscated JavaScript by a novel method of tokenizing JavaScript text at letter level and information-theoretic measures, based on the previous work in the domain of detecting obfuscated malicious code as well as the pattern analysis of natural languages. The new approach is apparently time efficient compared to existing systems since it processes much less objects while it is also proved to be able to reach the acceptable detection accuracies.
Research and Implementation on Machine Learning-based Detection of Malicious Script Codes
”
JSObfusDetector: A Binary PSO-based One-Class Classifier Ensemble to Detect Obfuscated JavaScript Code
” in
DOI:10.1109/AISP.2015.7123508
URL
[Cited within: 1]
JavaScript code obfuscation has become a major technique used by malware writers to evade static analysis techniques. Over the past years, a number of dynamic analysis techniques have been proposed to detect obfuscated malicious JavaScript code at runtime. However, because of their runtime overheads, these techniques are slow and thus not widely used in practice. On the other hand, since a large quantity of benign JavaScript code is obfuscated to protect intellectual property, it is not effective to use the intrinsic features of obfuscated JavaScript code for static analysis purposes. Therefore, we are forced to distinguish between obfuscated and non-obfuscated JavaScript code so that we can devise an efficient and effective analysis technique to detect malicious JavaScript code. In this paper, we address this issue by presenting JSObfusDetector, a novel one-class classifier ensemble to detect obfuscated JavaScript code. To construct the classifier ensemble, we apply a binary particle swarm optimization (PSO) algorithm, called ParticlePruner, on an initial ensemble of one-class SVM classifiers to find a sub-ensemble whose members are both accurate and have diversity in their outputs. We evaluate JSObfusDetector using a dataset of obfuscated and non-obfuscated JavaScript code. The experimental results show that JSObfusDetector can achieve about 97% precision, 91 % recall, and 94% F-measure.
Detecting and De-Obfuscating Obfuscated Malicous JavaScript Code
,”
Microarray Data Normalization and Transformation
,”
Investigation of Normalization Methods in Speaker Adaptation of Deep Neural Network Using Ivector
,”The deep neural network( DNN) was a remarkable modeling technology for speech recognition in recent years and its performance was significantly better than that of the Gaussian mixture model, which was the mainstream modeling technology in speech recognition before.However,commendable adaptation of DNN has not been solved yet. In this work,we use the identity vector( i-vector) to adapt a deep neural network by putting i-vector and the regular speech features together as the input of DNN for both training and testing. Then we focus on the normalization method of i-vector using a new max-min linear normalization method. We get a 5. 10% relative decrease in word error rate over the traditional length normalization method.
Speech Recognition Adaptive Clustering Feature Extraction Algorithms based on thek-Means Algorithm and the Normalized Intra-Class Variance
,”
ImageNet Classification with Deep Convolutional Neural Networks
,”
DOI:10.1145/3065386
URL
[Cited within: 1]
Abstract We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 dif-ferent classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0% which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully-connected layers with a final 1000-way softmax. To make train-ing faster, we used non-saturating neurons and a very efficient GPU implemen-tation of the convolution operation. To reduce overfitting in the fully-connected layers we employed a recently-developed regularization method called "dropout" that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry.
Overfitting and Undercomputing in Machine Learning
,”
DOI:10.1145/212094.212114
URL
[Cited within: 1]
ABSTRACT suggests a reasonable line of research: find algorithms that can search the hypothesis class better. Hence, there is been extensive research in applying second-order methods to fit neural networks and in conducting much more thorough searches in learning decision trees and rule sets. Ironically, when these algorithms were tested on real datasets, it was found that their performance was often worse than simple gradient descent or greedy search [3, 5]. In short: it appears to be better not to optimize! One of the other important trends in machine learning research has been the establishment and nurturing of connections between various previously-disparate fields including computational learning theory, connectionist learning, symbolic learning, and statistics. The connection to statistics was crucial in resolving this paradox. The key problem arises from the structure of the machine learning task. A learning algorithm is trained on a set of training data, but then it is applied to make
Feature Selection for Classification: A Review
,”

{kind=link}
{kind=link}