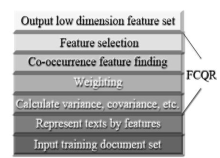
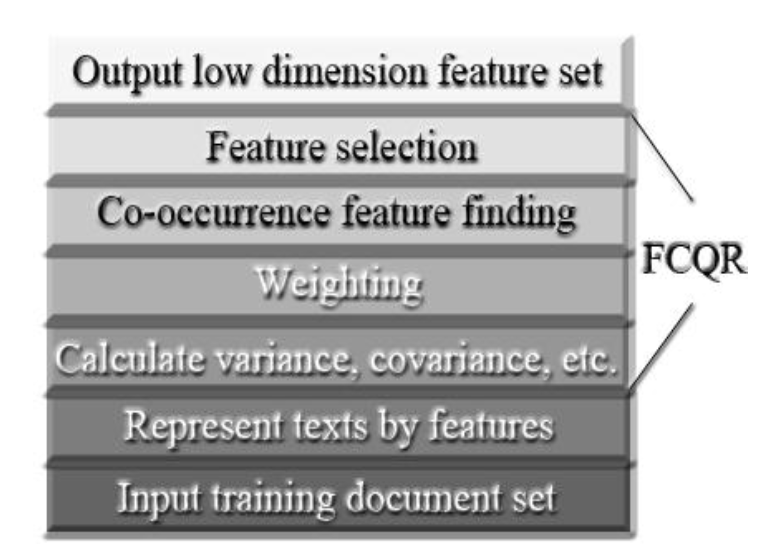
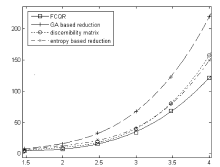
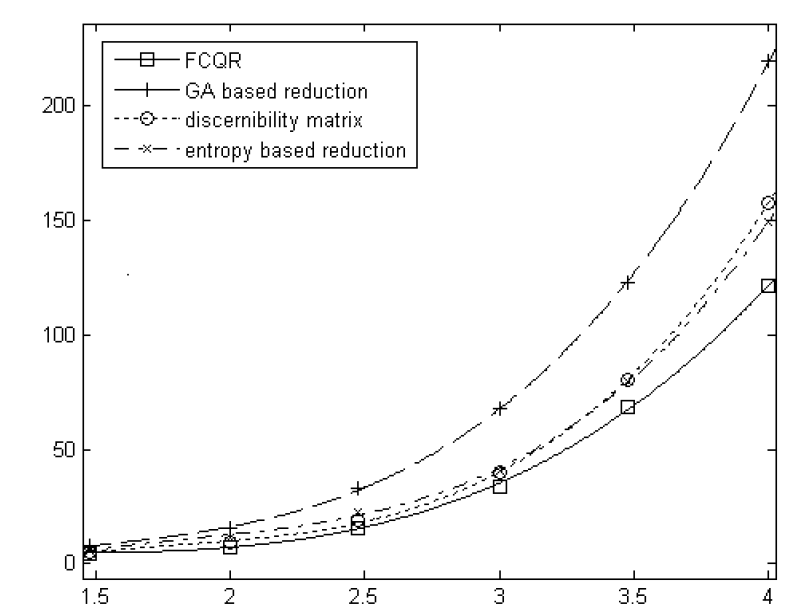
| [1] |
A. Yindalon, D. F. Lawrence, Z. Li, R.P. Eric, E. Efstathiadis , “A Comprehensive Empirical Comparison of Modern Supervised Classification and Feature Selection Methods for Text Categorization,” Journal of the Association for Information Science and Technology, Vol.42, No.10, pp. 1964-1987, October 2014
|
| [2] |
P. T. Fernando, J. Cardiff, P. Rosso, P. David , “Weblog and Short Text Feature Extraction and Impact on Categorization,” Journal of Intelligent & Fuzzy Systems, Vol.27, No. 52014, pp. 2529-2544, May 2016
|
| [3] |
R. S. Bhalerao, J. Y. Ollitrault, P. Subrata , “Principal Component Analysis of Event-by-Event Fluctuations,”Physical Review Letters, Vol.114, pp. 1-6, December 2015
|
| [4] |
M. Z. Ming , “Sparse Principal Component Analysis and Iterative Thresholding,” Annals of Statistics, Vol.41, No. 2, pp. 772-801, February 2013
|
| [5] |
J. Guia, Z. Suna, W. Jia , “Discriminant Sparse Neighborhood Preserving Embedding for Face Recognition,”Pattern Recognition, Vol.45, No. 8, pp. 2884-2893, August 2012
|
| [6] |
R. Karbauskaitė, O. Kurasova, G. Dzemyda , “Selection of the Number of Neighbors of Each Data Point for the Locally Linear Embedding Algorithm,” Information Technology and Control, Vol.36, No.4, pp. 359-364, April 2015
|
| [7] |
F. Y. Cao, J.Y. Liang, D.Y. Li , “A Dissimilarity Measure for the k-Modes Clustering Algorithm,” KNOWLEDGE-BASED SYSTEMS, Vol.26, No. 2, pp. 120-127, May 2014
|
| [8] |
K. Devarajan, G. L. Wang, N. Ebrahimi , “A Unified Statistical Approach to Non-Negative Matrix Factorization and Probabilistic Latent Semantic Indexing,”MACHINE LEARNING,Vol. 99, pp. 137-163, 2015
|
| [9] |
D. Q. Miao, H. Y. Duan, N. J. Zhang , “Rough Set based Hybrid Algorithm for Text Classification,” Expert Systems with Applications, Vol.36, No. 5, pp. 9168-9174, 2009
|
| [10] |
Y.S. Lee, L. Rocky, C. Y. Chen, P. C. Lin, J. C. Wang , “News Topics Categorization using Latent Dirichlet Allocation and Sparse Representation Classifier,” in Proceedings of IEEE International Conference on Consumer Electronics, pp. 126-13, Taipei, Taiwan, June 2015
|
| [11] |
Polkowski, Lech, Shusaku Tsumoto, and Tsau Y. Lin,Rough Set Methods and Applications: New Developments in Knowledge Discovery in Information Systems,Vol. 56, Physica, 2012
|
| [12] |
J. Dai and H. Tian, “Fuzzy Rough Set Model for Set-Valued Data,”Fuzzy Set and Systems,Vol. 229, No. 7, pp. 54-68, July 2013
|
| [13] |
S. B. Kanti, S. S. Sankar, C. Kripasindhu , “A Genetic Algorithm-based Rule Extraction System,” Applied Soft Computing,Vol.12, No. 1, pp. 238-254 January 2013
|
| [14] |
C. C. Yeh, D. J. Chi, T. Y. Lin, S. H. Chiu , “A Hybrid Detecting Fraudulent Financial Statements Model using Rough Set Theory and Support Vector Machines,” Cybernetics and Systems, Vol.47, No. 4, pp. 261-276, April 2016
|
| [15] |
H. M. Chen, T. R. Li, C. Luo, S. J. Horng, G. Y. Wang , “A Decision-Theoretic Rough Set Approach for Dynamic Data Mining,” IEEE Transactions on Fuzzy Systems, Vol.23, No. 6, pp. 1958-1970, June 2015
|
| [16] |
X. Y . Chen and S. Y. Wu, “The Optimization Assignment Model of Multi-Sensor Resource Management based on Rough Entropy,” International Journal of Grid and Utility Computing, Vol.8, No. 5, pp. 233-244, August 2015
|
| [17] |
Y. H. Han, Y. Yang, Z. G. Ma, Y. Yan, N. Sebe, X.F. Zhou , “Semi-Supervised Feature Selection via Spline Regression for Video Semantic Recognition,” IEEE Transactions on Neural Networks and Learning Systems, Vol.26, No. 2, pp. 252-264, February 2015
|
| [18] |
W. Z. Wu, Y. H. Xu, M. W. Shao, G. Y. Wang , “Axiomatic Characterizations of (S, T)-Fuzzy Rough Approximation Operators,” Information Sciences, Vol. 334, pp. 17-43, September 2016
|


 ), Qimin Caob, and Ning Xub
), Qimin Caob, and Ning Xub